Outlier detection techniques are widely used for solving tasks such as fraud detection, anomalous tissue detection in medical imaging data, or improving voice recognition models. By cleaning training datasets of outlying data points, unsupervised machine learning algorithms also benefit from a significant performance increase.
This report investigates the Generative Adversarial Network model, a technique for training generative models to learn the underlying probability distribution of an arbitrary training dataset through discirminative means. The work carried on in this project shows how the latent space of a Generative Adversarial Network model can be exploited for the task of outlier detection in Computer Vision tasks, as well as providing an extension that allows a Generative Adversarial Network to detect outliers in generic, high-dimensional datasets.
Chapter 1 - Introduction
The adoption of deep learning models in various fields of study has increased in recent years due to the reduced cost of training, and state of the art performance. This boost in performance and accuracy of deep learning models can be attributed, in part, to the prevalence of large-scale datasets for various tasks and fields of study.
With datasets such as the ImageNet Large Scale Visual Recognition Challenge (Russakovsky et al., 2015), which currently contains over 9 million images, the human effort required for sifting through these datasets for data cleaning and outlier removal purposes increases exponentially, to the point of intractability.
Besides playing a big part in imporiving the accuracy and performance of machine learning models,outlier detection algorithms have deep practical ramifications in today’s data-driven world. Currently, outlier detection mechanisms are being used for a range of activities, including, but not limited to building robust voice recognition models and fraudulent activity detection.
The Generative Adversarial Network (GAN) model is a breakthrough method for training neural networks to imitate arbitrary data distributions, which consistently outperformns strictly generative models (Goodfellow et al., 2014) in high dimensional tasks such as image generation (Goodfellow et al., 2014).
Given such performance of the GAN model, we hypothesise that a GAN-based outlier detection system will be able to outperform strictly generative models for outlier detection.
In this project, we leverage the power of GANs to learn and imitate specific data distributions in order to build a GAN-based algorithm for outlier detection in high-dimensional datasets.
Chapter 2 - Background Literature
2.1 Current state of Outlier Detection algorithms
The task of outlier detection, also reffered to as anomaly or novelty detection, involves training an algorithm to identify test data which is significally different to the training data. Outlier detection algorithms borrow techniques from various fields of study, including statistics and immunology.
Most of these algorithms aim to learn to model ’normality’, and then identify outliers using various metrics of dissimilarity between their learned model of ’normality’ and the test data.
According to Pimentel et al. (2014), outlier detection systems follow five general categories: probabilistic, distance-based, reconstruction-based, domain-based and informatic-theoretic techniques.
2.1.1 Probabilistic methods
Probabilistic outlier detection systems use a generative model to learn the probability density of normality. Their assumption is that test data that lies in regions of low probability density has a higher likelihood of being anomalous. Most of these probabilistic models impose a threshold on the likelihood of a test candidate belonging to the ’normal’ class, and flag all data that falls under this imposed threshold.
Probabilistic methods can be split into parametric and non-parametric models.
Parametric models, like the Gaussian Mixture Model (GMM), make assumptions about the distribution of the data. In GMMs, this extends to assuming that the data distribution can be estimated from a weighted sum of a Gaussian distributions, parametereised by the number of Gaussian prototypes considered.
Non-parametric models, such as Kernel Density Estimation (KDE), do not assume a fixed structure to a model. In the case of KDE, the functional form of the data distribution is estimated from the individual contributions of kernels placed on each data point in the dataset. In most cases, these kernels are Gaussian distributions.
While these models are simple to implement, and their outputs can be investigated using standard statistical tools, probabilistic models suffer from performance degradation when applied to high-dimensional datasets. The increase in dimensionality also increases the volume occupied by the data in the higher dimensional space, and thus sparsity. Sparse datasets can cause the estimated distribution to be wildly different to the actual distribution of the data.
2.1.2 Distance-based methods
Distance-based methods usually employ the use of clustering or nearest-neighbour methods for outlier detection. Their premise is that anomalous data will have an increased distance to it’s nearest neighbours, compared to normal data.
Even though these methods to not require us to impose prior assumptions on the training data, algorithms such as k-nearest neighbours do require suitable distance measures between data points. Inspecting high-dimensional datasets using distance-based methods is computationally expensive, as we need to compute the distance from each point to every other point in the dataset in order to determine the nearest neighbours. These methods can also suffer from the sparsity brought by increasing dimensionality.
2.1.3 Reconstruction-based methods
In reconstruction-based algorithms, a model of normality is learned by performing regression on the clean dataset. A reconstruction error is then computed between the regression target and the value of the test candidate when mapped using the regression model. Since outliers were not accounted for during training, these will
have a larger reconstruction error than clean data, and thus they can be flagged for removal.
Some of the reconstruction-based methods include neural network models such as Multilayer Perceptrons or Autoencoders. In Autoencoder-based solutions, the model is trained to learn to replicate the input through an arbitrary number of hidden layers. Outliers are then detected when attempting to reconstruct a test candidate leads to a high reconstruction loss.
Pimentel et al. (2014) describes these methods, and especially neural network based approaches to be sensitive to changes in hyperparameters, especially when using high-dimensional datasets.
2.1.4 Domain-based methods
Domain-based methods attempt to enclose the ’normal’ data inside a boundary. This is similar to the probabilistic methods, yet these models are insensitive to the density of the data. Here, outliers are identified based on their location, and whether they are a member of the domain of the training data.
Because this membership problem is very similar to a two-class classifcation problem, Support Vector Machines (SVMs) are a very popular technique for domainbased outlier detection.
2.1.5 Information-theoretic models
With information-theoretic models, we use techniques such as entropy to compute the information in a dataset.
These models assume that anomalies will significantly alter the entropy of a ‘clean’ dataset. Therefore, by computing the information content of the whole dataset, including outliers, and then progressively removing subsets from the dataset, we can identify subsets containing outliers from the large information loss suffered in response to removal.
However, depending on the metric used, these models may only be reliable when a big number of anomalous entries are present in the dataset.
2.2 The Generative Adversarial Network Model
At its core, a neural network uses matrix multiplications parameterised by weights in order to compute linear transformations of the input. In order to train a network to learn a task, the weights of the matrix multiplications have to be updated to bring our network’s output as close as possible to the desired target. This is achieved by computing an objective loss function between the output and the target, and then performing backpropagation to update the weights with respect to the loss value.
By optimising the model so that its predictions are as close to their respective target labels as possible, the model can achieve good prediction results during tests on unseen data.
A model can also be trained in an unsupervised manner, by not providing labels against which our model’s predictions are compared. This can allow the model to learn its own representations for the training data, potentially leading to more complex feature extraction, and pattern identification that was not obvious to a human observer. All of these can help increase the performance of the model and provide more meaning for a human investigating the dataset.
The Generative Adversarial Model is a neural network model that is trained using a semi-supervised approach. Here, the neural network model does not aim to optimise a single objective loss function, but instead it aims to achieve an equilibrium between two adversaries, where neither of them can make a gain from a strategy change, provided the adversary’s strategy remains constant.
In GANs, these two adversaries are the generator and the discriminator. The discriminator’s aim is to distinguish between samples that came from the training data distribution and samples that came from the generator’s distribution. The only set of labels provided to the discriminator are the origin of the data it has just seen, namely, whether it came from the training set, or it was generated by the generator. On the other hand, the generator’s aim is to create realistic samples that are ambiguous to the discriminator, causing it to misclassify generated data coming from the generator as training data.
This adversarial game played by the generator and discriminator can be described using the minimax decision strategy found in Game Theory, as the generator attepmts to min imize the max imum loss that it can incur from the discriminator’s decision.
2.2.1 Structure
In a GAN, the two adversaries engaged in a minimax game are represented by neural networks. The discriminator’s goal is to maximise the accuracy with which it can distinguish real samples that came from the training set from fake samples that were generated by the generator. At the same time, the generator is trying to minimise the likelihood that its generated samples are identified as being fake by the discriminator.
As the discriminator learns to better model and extract patterns for discerning between training and fake data, the only way for the generator to ‘keep up’ with the discriminator’s progress is for it to progressively mimick the training data distribution with increasing accuracy.
At the end of the adversarial training, the generator’s samples are so accurate that the discriminator is unable to distinguish training (real) data from generated (fake) data.
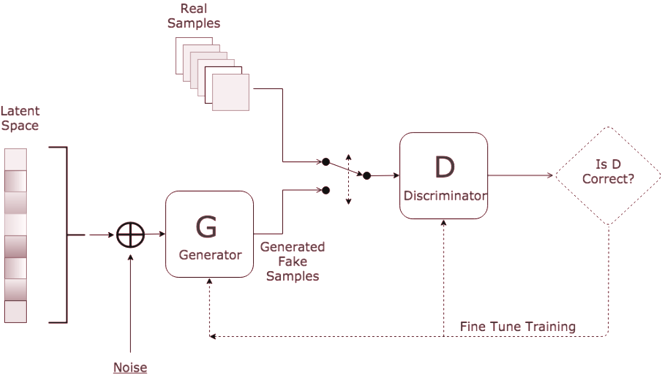
The adversarial game played by the generator and discriminator can be explained through the analogy of the bank and the currency forger. Here, the generator plays the role of a currency forger trying to produce counterfeit currency. The bank, played by the discriminator, will investigate the notes produced by the forger and give a response on whether or not the currency is real or counterfeit. In the case where the notes are declined by the bank for being counterfeit, the forger will alter
the counterfeiting process, thus producing a different counterfeit note. The bank also alters it’s checking process to account for this new counterfeiting method. This process is repeated until the bank is unable to tell fake notes apart from real notes. In this case, the rate at which the bank erroneously rejects legitimate notes is the same as the rate at which the bank erroneously accepts counterfeit notes.
2.2.2 Training Algorithm
As stated above, a Generative Adversarial Network (GAN) is comprised of two neural network adversaries: the generator G , and the discriminator D .
The generator aims to generate output that could be realistically mistaken for Thus, we aim so that when given a random as input, the generator’s outputs will follow a probability distribution,
samples taken from the training set, X = { X (1) , X (2) , . . . , X ( n ) } . to train the generator to learn a mapping G ( z ; θ G ), vector z p G , that is similar to the probability distribution of the training data, p X .
During training, the parameters of the generator, θ G , are optimised to improve the output of G .
The random input vector, z ∼ p z , is sampled from an aribtrary probability distribution, p z , which is typically either a uniform or a normal distribution. The probability distribution, p z , constitutes the latent space of the generator.
The discriminator, D ( X ( ) i ; θ D ), where θ D models the parameters of the discriminator network, and X ( ) i represents a feature vector sampled from the training set X , is trained to output the probability that a certain data point, X ( ) i , came from the training data rather than p G (Goodfellow et al., 2014).
The two networks D and G are played against each other in a two-player minimax game where the generator tries to ‘fool’ the discriminator that the generated data actually came from the training set. This game can be represented mathematically as V(D,G) (Goodfellow et al., 2014):
After training, the discriminator’s prediction accuracy should be no better than chance, i.e. 50%, as the generator’s samples are almost identical to the training data. At this stage, sampling data from p X or p G is synonymous.
Algorithmically, the process of training a Generative Adversarial Network can be represented as in Algorithm 1.
Algorithm 1 GAN training algorithm
- 1: G ( z ; θ g ) ← build generator
- 2: D ( X ; θ d ) ← build discriminator
- 3: for epoch ∈ [0; number of epochs):
- 4: z ← sample noise { z (1) , z (2) , …, z ( m ) } from p z
- 5: data real ← sample data { X (1) , X (2) , …, X ( m ) } from p X
- 6: data fake ← G ( z ; θ g )
- 7: loss ( real ) D ← E x ∼ p X ( x ) [log D data [ real ; θ d )] // cross entropy loss
- 8: loss ( fake ) D ← E z ∼ p z ( z ) [log(1 -D G z,θ ( ( g ); θ d ))] // cross entropy loss
- ( real ) ( fake )
- 9: loss D ← loss D + loss D
- 10: θ d ← backpropagate( loss D )
- 11: z ← sample noise { z (1) , z (2) , …, z ( m ) } from p z
- 12: loss G ← E z ∼ p z ( z ) [log D G z,θ ( ( g ); θ d )] // cross entropy loss
- 13: θ g ← backpropagate( loss G )
2.2.3 Implementing GAN architectures
In the original paper by Goodfellow et al. (2014), the generator is a multilayer perceptron with its input being a single noise vector z and output having the same dimensions as the training data.
The discriminator is also represented as a multilayer perceptron, taking in a feature vector with the same shape as the shape of the training data, and outputting a single scalar value between 0 and 1.
The output shape of the generator must match the input shape accepted by the discriminator, as the generator’s output is being fed directly into the discriminator.
After setting up the two neural networks, the next step is to define the loss function for the discriminator and the generator.
The output of the discriminator is bounded between 0 and 1, with 0 meaning that the input is predicted to have come from the training set and 1 meaning that the input has been generated by the generator.
In order to compute the loss, the output of the discriminator is compared against the labels (0 & 1) using the sigmoid cross-entropy function, S H p,q ( ( )). This function is bounded in the range [0; 1], and therefore its output will constitute the probability of a sample being fake.
The sigmoid cross-entropy function is the function composition of the cross-entropy function and the sigmoid function, S H p,q ( ( )), where p and q are probability distributions and S x ( ) and H p,q ( ) are defined in Equation 2.2 and respectively Equation 2.3.
The generator’s loss is derived by computing the sigmoid cross-entropy between a zero vector and the discriminator’s output when given the generator’s output as input.
By setting up the model’s losses in this way, the Network behaves in accordance to the adversarial minimax game defined in Equation 2.1.
To compute the gradients and update each model’s weights, the original paper suggests using stochastic gradient descent. However, a faster convergence, as well as prevetion from converging to a local optimum can be achieved by substituting stochastic gradient descent for the Adam optimiser (Kingma and Ba, 2015).
2.2.3.1 Best practices
Optimising a GAN can be thought of as reaching a Nash equilibrium between the generator and the discriminator, where none of the two can make a gain based on a unilateral change in strategy, given that the other adversary’s strategy remains constant.
This method of optimisation, despite its intuitive nature, makes it very difficult to train GANs to convergence, and makes the training process very unstable and noisy.
While effors have been made to stabilise GAN training, throuhg the invention of the Wasserstein GAN (Arjovsky et al., 2017), training GANs is still an ambiguous process that many times feels like interacting with a black box.
This section was written to demistify and troubleshoot common problems that arise during GAN training. By reading this section, the reader can understand some of the best practices that should be employed when training GANs.
One of the first difficulties encountered when training GANs is the possibility of having vanishing gradients for the generator.
In the vanishing gradient problem, the gradients computed when calculating the loss are so small that the changes backpropagated through the network are insignificant. This leads to the network converging to a sub-optimal solution.
One way of solving this problem is to simply switch over the ‘fake’ / ‘real’ labels, so that 0 now represents ‘fake’ and 1 represents ‘real’. An alternative would be to change the optimisation of the generator, so that instead of minimising log(1 -D G ( ( z ))), the generator could be maximising log D G ( ( z )).
Secondly, sampling the random noise vector z from a normal distribution yields much better results than sampling from a uniform distribution. This discovery was made when I noticed a performance improvement in the experiments detailed in Chapter 3 following this change.
Thirdly, a big performance increase can be brought to the model by scaling the input to the discriminator to have zero mean and unit variance. This can be done in the generator by using the hyperbolic tangent function, tanh as the output of the final layer of the generator, thus making the generated data only have values between -1 and 1.
Moreover, maintaining zero mean and unit variance throughout the network, as the input passes from one layer to another is a good way of preventing the vanishing gradient problem. This can be done by implementing batch normalisation between the layers of the network.
Another big performance increase comes from preventing the network from overfitting. Overfitting in GANs happens when the generator only learns to imitate a certain part of the distribution of the discriminator, yet the discriminator can still be fooled to think that the data resembles the training data. To avoid this, a good practice is using dropout, a technique that turns of random neurons in the network at a certain rate, thus forcing the model to find new pathways for arriving at the correct output. This technique should be implemented in both the generator and the discriminator. Experimentally, I found that a rate of 0.5 is enough to prevent overfitting.
Finally, mode collapse is a big issue that arises when attempting to train GANs to learn multimodal distributions.
In this case, a generator can learn to only generate realistic samples from one of the peaks of the distribution, thus still bypassing the discriminator’s checks, without learning the full distribution of the training data. This is problematic, as the disciminator will eventually catch up, learning to discredit samples coming from that certain peak.
In this case, there is a chance that the generator will ‘jump’ to generating samples from the other peak of the multimodal distribution, leading to a process that will continue ad nauseam , with neither the generator nor discriminator converging to an optimal solution
In the case of mode collapse, one solution involves evaluating an entire sample of generated data, rather than individual samples, thus encouraging diversity. Another technique involves showing fake samples from previous training epochs to the discriminator, to prevent it from ‘forgetting’ the previous techniques employed by the generator.
Chapter 3 - Framework implementation
3.1 Experimentation with GAN
Early experiments revolved around renowned GAN papers such as Radford et al. (2015) and Goodfellow et al. (2014), and involved reimplementing the author’s models and replicating their results.
The purpose of the work conducted in this chapter was to understand the GAN model and proper training of GANs, so that I could be well equiped to tackle building an outlier detection model using GAN.
3.1.1 Imitating a 1D Gaussian distribution
We constructed a GAN based on Goodfellow et al. (2014), using two adversarial Multilayer Perceptrons as the discriminator-generator adversarial pair.
The training data input to the discriminator consisted of batches of 100-dimensional vectors sampled from a 1 dimensional normal distribution with mean µ = 4 and standard deviation σ = 1 25. . The input to the generator consisted of batches of 100-dimensional vectors sampled from a uniform distribution between -1 and 1.
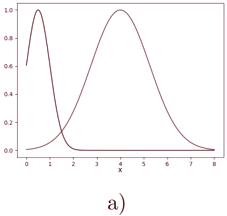
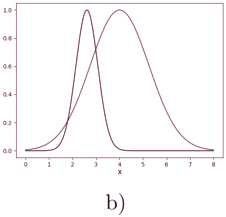
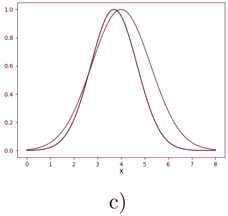
For this experiment, the GAN has been trained for 20000 epochs using a modification of mini-batch gradient descent, the Adam optimizer (Kingma and Ba, 2015).
Following the author’s hyperparameter configuration, and using two multilayer perceptrons as the generator and discriminator, I arrived at the same results as the author, which can be seen in Figure 3.1.
3.1.2 Imitating a high dimensional wine property dataset
Even though Section 3.1.1 is a clear indication that GANs are capable of imitating and generating vectors that have a normal distribution of arbitrary mean and variance, this can be considered an easy tast, as it only involves learning a mapping from one 100-dimensional space to another 100-dimensional space.
Therefore, I investigated whether GANs are capable of imitating distributions that were not artificially generated, such as our normal distribution in Section 3.1.1.
For this, I chose to see whether a GAN can learn the underlying probability distribution of an 11-dimensional dataset representing sets of chemical properties of various wines from the Wine Quality dataset by Cortez et al. (2009).
This dataset is made up of 6497 12-dimensional feature vectors representing various properties of red and white wines, including their alcohol by volume content, pH and residual sugar. The last component of the vectors represents the wine quality. I stripped away this component, considering it as a label to be used for regression/classification tasks.
| fixed acidity | volatile acidity | citric acid | residual sugar | … | quality |
|---|---|---|---|---|---|
| 7 | 0.27 | 0.36 | 20.7 | … | 6 |
| 6.3 | 0.3 | 0.34 | 1.6 | … | 6 |
| 8.1 | 0.28 | 0.4 | 6.9 | … | 6 |
| 7.2 | 0.23 | 0.32 | 8.5 | … | 6 |
| … | … | … | … | … | … |
The part of the first 4 entries of the dataset is shown in Table 3.1 (some columns were excluded for visibility).
This dataset constitutes a good choice for a GAN benchmarking experiment, as it is a high dimensional dataset, with feature vectors spanning 11 dimensions. Another property of this dataset is that it is not normally distributed, thus posing more of a challenge for a GAN imitating this distribution.
The only change to the model that was needed when moving from the 1-dimensional case presented in Section 3.1.1, was increasing the width of the input, output and hidden layers of both the generator and the discriminator, in order to allow the GAN to have more expressive power.
The hyperparameter configuration of this model can be found in Appendix A.
As suggesed in Section 2.2.3.1, the dataset was scaled so that each feature has zero mean and unit variance. This is generally a good practice in any situation when training GANs, as it prevents issues such as vanishing/exploding gradients during backpropagation. In this case, this choice serves to reduce the sparsity in the dataset, and help the generator learn the data distribution easier.
Without scaling, different features of the dataset differ, in some cases, by orders of magnitude. For example, the value of sulfur dioxide in a wine could be as high as 440, while the volatile acidity could be as low as 0.08.
This could prove problematic, as it forces the generator to learn a very sparse distribution, and it means that the weights have to be optimised in such way that the generator is able to generate both very large numbers, as well as subunitary values.
Training the GAN for 30000 epochs using the Adam optimiser (Kingma and Ba, 2015), the generator successfully learns how to generate wines with realistic properties that follow the properties of the training dataset. This is clearly seen in the violin plot in Figure 3.2, where we see that the generator captures the mean and spread of each feature. Tables 3.2 and 3.3 also show samples from the generator and traning data to emphasize this.
| fixed acidity | volatile acidity | citric acid | residual sugar | … | alcohol |
|---|---|---|---|---|---|
| 6.2 | 0.21 | 0.29 | 1.6 | … | 11.2 |
| 6.6 | 0.32 | 0.36 | 8 | … | 9.6 |
| 6 | 0.21 | 0.38 | 0.8 | … | 11.8 |
| fixed acidity | volatile acidity | citric acid | residual sugar | … | alcohol |
|---|---|---|---|---|---|
| 8.37 | 0.36 | 0.47 | 2.45 | … | 9.26 |
| 10 | 0.25 | 0.41 | 2.37 | … | 9.55 |
| 7.7 | 0.41 | 0.16 | 1.91 | … | 9.31 |
Note: the data presented above was rescaled back to the original values before presentation.
Violin plot Generated vs Training Attributes
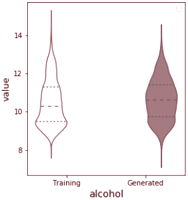
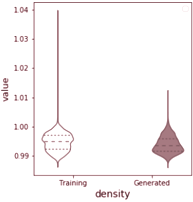
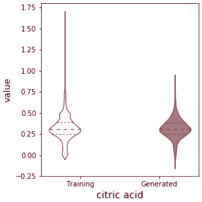
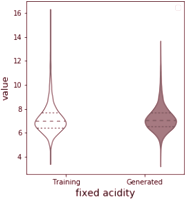
By projecting the generator output as well as the actual training dataset into a lower dimension, using dimensionality reduction techniques such as t-SNE (Van Der Maaten and Hinton, 2008) and Principal Component Analysis (PCA) (Pearson, 1901), we can more clearly visualise and confirm that indeed, the generator did learn how to reproduce the underlying probability distribution of the wine quality dataset (Cortez et al., 2009). Figure 3.3 shows the 2-dimensional projections using t-SNE and PCA.
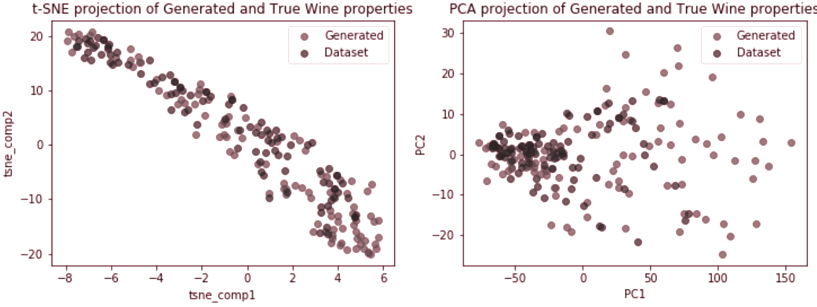
3.1.3 Imitating handwritten digits using DCGAN
GANs need not be restricted to MLP-based architectures. The models used for the generator and discriminator can be swapped with different architectures depending on the task that is being attempted.
In the following experiment, I investigate a GAN’s ability of generating realistic handwritten digits similar to the 28x28 pixel, grayscale images found in the MNIST dataset (LeCun et al., 2010).
My approach to this problem involves using a Deep Convolutional GAN (DCGAN) model, similar to the one in Radford et al. (2015). In this implementation, the architecture was scaled down and adapted for 28x28x1 images, down from 64x64x3, as in the original paper.
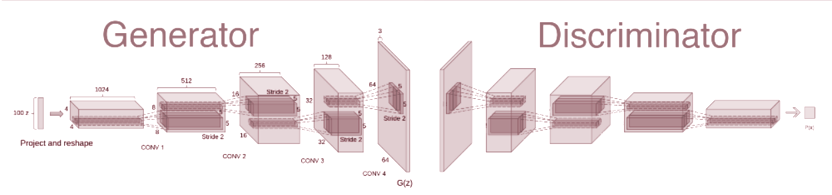
In this experiment, the MLPs in both the generator and discriminator are replaced with Convolutional Neural Networks (CNN).
The generator’s architecture is made up of strided transposed convolutional layers (see Figure C.1), each of them having their input scaled and shifted using batch normalisation in order to prevent internal covariate shift. As a non-linearity, each layer of the generator uses a ReLU activation, except for the last one which uses a tanh activation in order to squash the output of each pixel between -1 and 1.
Similarly, the discriminator uses strided convolutional layers with a stride of 2, batch normalisation in each of the layers, and a LeakyReLU activation for each of the layers, except for the output, which is squashed using a sigmoid activation.
To prevent overfitting in the discriminator, the original DCGAN model had to be altered, introducing dropout at a rate of 0.25 in each of the layers of the discriminator. This modification was successful, and after training we obtained results similar to the results of the authors of (Radford et al., 2015). These results are present in Figure 3.5.

3.2 AnoGAN: GAN-based Outlier Detection Model
Building on the outlier detection techniques described in Chapter 2, and the description of the GAN framework from Chapter 2.2, I introduce AnoGAN: an outlier detection model that uses a Generative Adverarial Network in order to identify and highlight anomalous regions in medical imaging files (Schlegl et al., 2017).
In this chapter, I detail the structure of the AnoGAN model, as well as how it can be applied to medical imaging data in order to flag anomalous samples and highlight anomamlous regions.
I will then present my own AnoGAN implementation, adapted for outlier detection in the MNIST dataset.
Finally, I will also tackle some of the shortcommings of the AnoGAN framework towards the end of this chapter.
In Schlegl et al. (2017), the authors propose an unsupervised method of learning a generative representation of local anatomical features, where GANs are trained to learn a generative model of features that make up healthy anatomical images.
After this model is trained on healthy data, the degree of ‘outlyingness’ of a test candidate is determined from the reconstruction error between the most similar image generated by the trained generator, and the test candidate.
Anomalous images are identified by having a high reconstruction error when compared to a generated sample. Theoretically, as a GAN is only learning the latent space representation of ‘healthy’ data, an anomalous test candidate would be impossible for the generator to imitate, and so its latent space mapping would fall outside the learned manifold of the generator after training.
Looking back at the Outlier Detection literature reviewed in Chapter 2, we can classify AnoGAN as a mix between a probabilistic and a reconstruction-based outlier detection model. The probabilistic nature of this model comes from the GAN component learning the underlying distribution of ’normality’, while the reconstruction side is brought forward by the backpropagation algorithm, which attempts to minimise a reconstruction error between the test candidate and the generated output.
The model implemented by the authors uses the DCGAN model proposed by Radford et al. (2015). Instead of using an MLP to map the noise vector to the output,
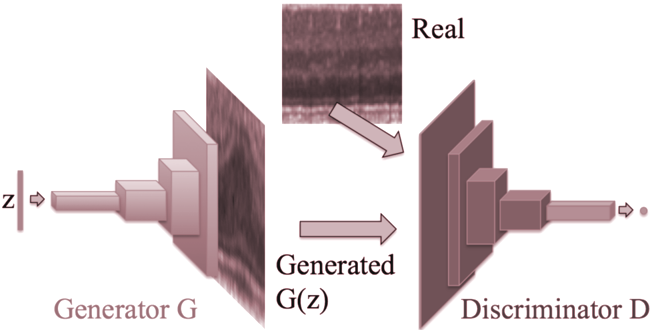
the authors make use of strided transposed convolutional and convolutional layers in the generator and discriminator. The architecture of AnoGAN is presented in Figure 3.6.
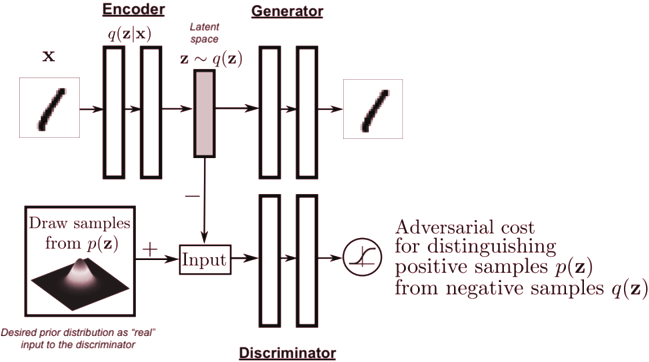
In AnoGAN, the generator is used as a function that can construct healthy anatomical images from a random noise vectors z . When investigating a test candidate for outlier detection, we aim to find a variable z in the latent space of the generator that, when mapped through the generator function, G ( z ), will yield an image that is visually similar to the test candidate.
The main issue with GANs, however, comes from having the generator map random noise vectors to meaningful output. As such, we do not have a direct mapping between a generated image and a point lying on the latent space of the generator. This mapping is thus inferred through the use of computer vision algorithms.
In order to find a latent space mapping of the test image, we sample z randomly, and then progressively update it’s values through 1 2 , , . . . , Γ backpropagation steps, minimising a loss function between the generated image and the test image.
In the original paper, the authors define an anomaly loss for updating the latent variable z , which is comprised of two separate loss functions, the residual loss L R ( z γ | x ), and the discriminator loss L D ( z γ | x ), both conditioned on the input x .
The residual loss function computes the sum of the pointwise difference between the input image and the image generated by the generator from z :
where z γ is the random input vector z at backpropagation step γ ∈ 1 2 , , . . . , Γ.
The discriminator loss makes use of the trained discriminator to compute a dissimilarity measure between the test and generated images.
Instead of using the discriminator to classify between real/fake input, the last fullyconnected layer of the discriminator is removed, effectively using of the penultimate fully-connected layer, as well as all the previous convolutional layers for computing a loss. Since the convolutional layers learn to extract patterns from images, we are essentially using our modified discriminator as a feature extractor rather than a ‘real’/‘fake’ classifier.
Thus, the discirmination loss is computed as:
where f ( ) is the penultimate fully-connected layer of the discriminator. ·
The final loss function will be the weighted sum of these two losses:
with λ balancing how much each of the individual losses contributes to the anomaly score.
The anomaly score of the input image is computed using the input vector z Γ , after Γ backpropagation steps, and is represented in Equation 3.4.
where R ( x ) = L R ( z Γ | x ) and D ( x ) = L D ( z Γ | x )
Anomalous regions in images can be pinpointed and highlighted by computing a residual image between the test candidate and the generated image at backpropagation step Γ. This residual image is represented in Equation 3.5.



3.2.1 AnoGAN: Adaptation for MNIST
By building on the work of Schlegl et al. (2017), I adapted and implemented a version of AnoGAN that is capable of identifying anomalous handwritten digit images, as well as highlighting the anomalous regions.
For this implementation, I based my model on the DCGAN model used for MNIST digit generation in Chapter 3, only adding the backpropagation outlier detection algorithm to this model.
After training, the generator is replicated for image generation. During the anomaly detection process, the generator’s weights are kept frozen, and the only variable that is updated through backpropagation is the z variable, by minimising the anomaly score 3.4.
Given an image test set X t = { X (1) t , X (2) t , …, X ( m ) t } , the anomaly score after Γ backpropagation steps is extracted using the outlier detection backpropagation algorithm, thus yielding scores { A ( X (1) t ) , A ( X (2) t ) , …, A ( X ( m ) t ) } .
3.2.1.1 Results
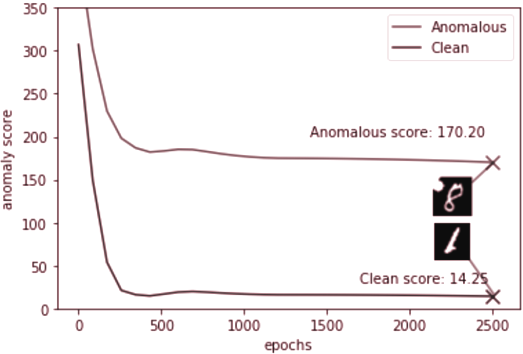
The MNIST AnoGAN test set contains 150 MNIST digits sampled from the MNIST test set. Out of these, 100 instances are clean images, while 50 of them are images which had blobs of random sizes added at random positions throughout the image (see Figure 3.8).


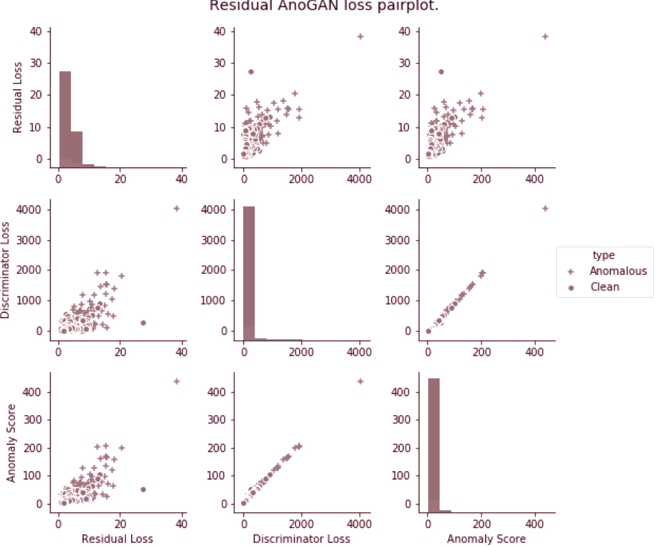
After running the anomaly detection algorithm, the convergence anomaly score, A ( X ( ) i t ), of each test image can be used for clean/anomalous classification. This can be done dynamically, without requiring us to impose a hard threshold value on the anomaly score of a test image. The significant difference in the convergence values of anomaly scores between clean and anomalous images offers a wide enough margin for classification, as can be seen in Figure 3.9.
This clear separation between losses is also seen in the residual images, where anomalous images have much larger anomalous areas (see Figure 3.10).

For clean/anomalous classification based on anomaly score, I used a Gaussian Mixture Model (GMM), a generative model in which random variables are sampled from a mixture of a finite number of Gaussian probability distributions. This can be thought of as a soft version of the k-means algorithm, where instead of performing a hard assignment on a data point to belong to an arbitrary cluster, we assign probabilities of a data point belonging to each of the clusters.
A problem that usually comes up when using a Gaussian Mixture Model is that the data is usually unlabelled, and therefore an educated guess has to be made as to how many classes (clusters) the model should use. In this case, this is not a problem, since we know that we want to classify the data as either clean or anomalous, so we will have only two clusters.
In order to compute the clusters, GMM uses the Estimation-Maximisation (EM) algorithm, which computes the likelihood of each data point with respect to a cluster, and then updates the cluster’s prototype to maximise the likelihood of the data being generated from that cluster’s distribution. Figure 3.11 shows a GMM
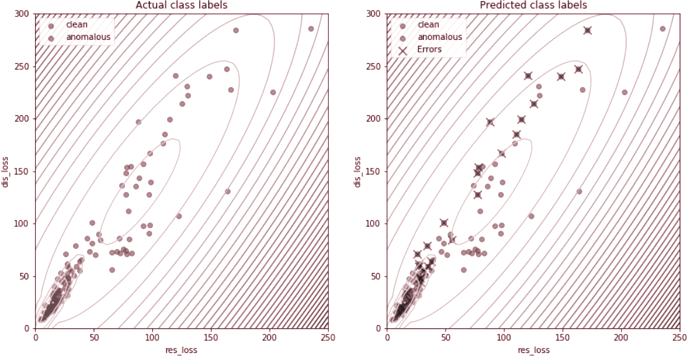
fitted to a scatter plot of residual losses against discriminator losses for the 150 test images.
I fitted two GMMs to the anomaly detection results on the 150 test images. One of them is a 2D GMM fitted around the residual-discriminator loss scatter plot, the other being fitted on the anomaly scores of the test images. Benchmarking these two models using a confusion matrix (see Table 3.4, the anomaly score can be observed as a more accurate metric for outlier detection, as opposed to the residual or discriminator losses by themselves.
| Accuracy | Error rate | Recall | Fallout | Specificity | Precision | Prevalence | |
|---|---|---|---|---|---|---|---|
| 2D GMM | 0.8 | 0.2 | 0.865 | 0.315 | 0.685 | 0.83 | 0.553 |
| 1D GMM | 0.813 | 0.187 | 0.875 | 0.296 | 0.704 | 0.84 | 0.56 |
From Figure 3.11, it can be observed that the clean images tend to cluster together in regions of low loss values, while the anomalous images are scattered further apart from each other in regions of higher loss values.

This is normal and expected, as during the adversarial training process, the AnoGAN learns the criteria for normalcy in clean images. Therefore, all clean images will have to meet the same criteria, and thus clustering tightly together in a region of small loss values. On the other hand, each anomalous image can be anomalous in its unique way, and therefore it is to be expected for the cluster of anomalous images to have a higher variance in loss values.
3.2.1.2 Interpolation errors
An interesting patterns arises when clean images have high loss values, as could be observed in Figure 3.11. This clearly shouldn’t be the case, as the AnoGAN model has seen very similar images in the training stage. Both Figure 3.12 and Figure 3.13 show how the generator is mistakenly generating digits that is has never seen during training, and do not look anything like the digits used in the training stage. In Figure 3.12, it appears that the generator is trying to generate the digit 4, when clearly it should be aiming to generate digit 6.
Similarly, all anomalous images should have higher loss values than the clean images, as the model hasn’t seen anything like them during the training process. This is clearly not the case in Figure 3.13, where the generator might be interpreting the test image as a backwards digit 6. This is clearly in error, and should not happen during the anomaly detection process.
We hypothesize that this might be due to a separated latent space from which the random noise vector z is being sampled.




By having gaps between classes, this allows for the noise vector z to fall in a optimal area between the classes, forcing the generator to interpolate between these two classes and generate mangled digits. Figure 3.14 shows latent space interpolation between two digits.
3.3 Generalising the AnoGAN model
3.3.1 Finding a substitute residual loss
For testing the applicability of the AnoGAN model to datasets outside the realm of Medical Imaging and Computer Vision, the AnoGAN model was benchmarked against the Wine Quality dataset (Cortez et al., 2009) described in Section 3.1.2.
The model used for this benchmark was almost identical to the model used for MNIST outlier detection in Chapter 3.2, the only modification being altering the shape of the output from the generator from a 784-dimensional to an 11dimensional vector, and adapting the discriminator’s expected input shape to account for this. This was done to accomodate the Wine Quality dataset, which consists of 11-dimensional vectors.
The AnoGAN experiment was re-ran on the Wine Quality dataset, training the GAN component for 30000 epochs, while using only ‘clean’ (normal wines, excluding wines with quality 9 and above) as training data.
After performing outlier detection on a test set consisting of 700 wines, out of which 35 (5%) of them had quality 9 or above, a high degree of overlap can be noticed in the loss values between outliers and normal data (Figure 3.15).
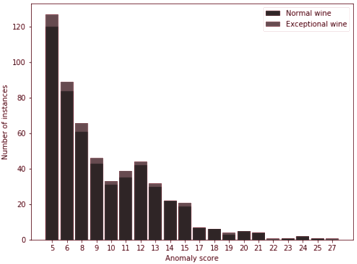
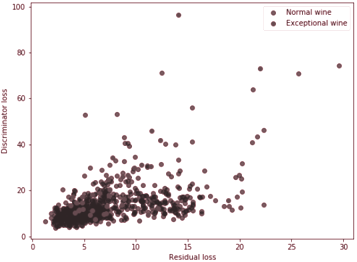
In benchmarks, the standard AnoGAN with residual loss obtains a performance which is no better than the performance of other outlier detection models such as the Gaussian Mixture Model or Kernel Density Estimation (Figure 3.16).
The main advantage of using a GAN for outlier detection was the possibility of creating a separation between clean and anomalous data, mainly represented through the discrepancy in loss values. As can be seen from Figure 3.15, this boundary can not be extracted from this result of anomaly detection.
This problem was not encountered while running the AnoGAN experiment on the MNIST dataset, even though the only variables between the two experiments were the datasets and the output shape of the generator. This difference may be brought forward by the increased sparsity of the 784-dimensional MNIST dataset, where the background of each digit (value 0) constitutes the bulk of the feature-vector. Because of the denser feature vectors exhibited in the wine quality dataset, it might be harder for the backpropagation algorithm to converge on a correct latent space representation of the test candidate.
This problem could be avoided by evaluating a distribution of test candidates against the outlier detection algorithm, and using a similarity metric between the distribution of the test candidate and the distribution of the generated output of the generator.
Since the generator is only capable of generating data that follows the same distribution as the one that was seen during training, any items outside the distribution of the generator can be flagged as anomalous, thus replacing the residual loss described in Schlegl et al. (2017).
I hypothesise that evaluating a measure of similarity between a sample of test candidates and a sample from the trained generator will provide a performance increase for the AnoGAN outlier detection algorithm.
3.3.2 Estimating the data distribution
In order to compute the information about the underlying distribution of each of the samples, each of the samples is estimated using Kernel Density Estimation (KDE).
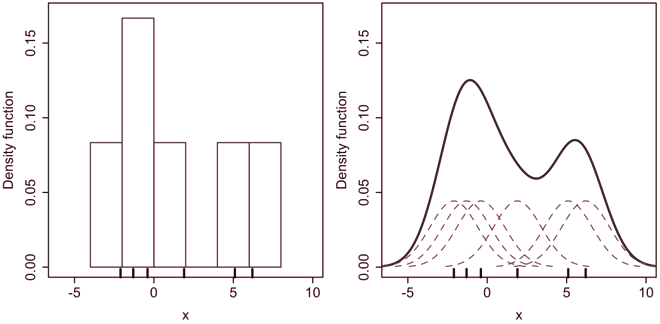
KDE is a technique that is similar to histogram binning, which replaces the need to parameterise bin numbers and bin edges, by placing a kernel function on top of each point in the sample (see Figure 3.17. The probability distribution of the estimation is thus computed from the contributions of each of the kernels.
Kernel Density Estimation is computed using the formula:
where K is a non-negative function (which must integrate to 1) which si applied to each of the points in the sample, h is the bandwidth (or spread) of the kernel, and n is the number of items in the sample.
For the purpose of this project, the AnoGAN model was implemented in the Tensorflow (Abadi et al., 2016) Python library for the entire implementation of AnoGAN. As Tensorflow does not include functionality for KDE, I implemented my own library of KDE functions from scratch (see Appendix B).
3.3.3 Bhattacharyya distance as similarity measure
glyph[negationslash]
For evaluating the While the Kullback-Lieber divergence (Equation 3.7) can be used as a similarity metric between two distributions by investigating the information content of each of the distributions, KL-divergence is not a valid distance metric between distributions, due to it’s lack of symmetry ( KL p q ( || ) = KL q p ( || )).
The Bhattacharyya distance (Bhattacharyya, 1946), however, is a valid statistial distance which is symmetric and can be used to evaluate the similarity of two distributions.
The Bhattacharyya distance is defined as:
where p and q are two probability distributions.
The probability distributions p and q are estimated using the aforementioned Kernel Density Estimation technique (using the custom Tensorflow libraries mentioned), and thus, the residual loss is substituted for the Bhattacharyya distance in the anomaly detection algorithm.
Chapter 4 - Evaluation
By evaluating the distribution of the test candidate against the distribution of generated data, and using Bhattacharyya distance as a similarity metric, I hypothesise that this extended AnoGAN form is capable of outperforming other generative outlier detection models, as well outperforming the classic, residual loss based AnoGAN described by ? .
The performance of the extended AnoGAN is benchmarked against some of the generative outlier detection systems presented in Chapter 2. The focus falls specifically on generative (or probabilistic) models, in order to evaluate whether the adversarial component of generative learning in GANs brings a benefit.
4.1 Test dataset
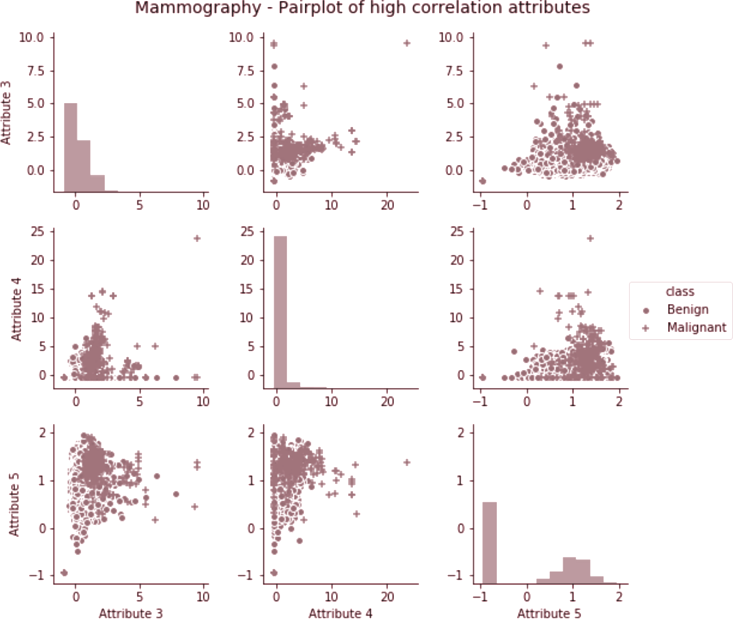
All the models that are evaluated in this section are going to be tested against the Mammography dataset from Woods et al. (1993), which is made up of 11183 samples of various features detected during mammographies. Out of the 11183 samples, 260 of them are samples where a malignancy has been detected. The small number of samples which are malignant makes this dataset very useful for testing outlier detection models.
Even though the model does not have names for the attributes, these are not needed for inferring properties of the dataset for data mining / data analysis work.
| No. | 1 | 2 | 3 | 4 | 5 | 6 | Class |
|---|---|---|---|---|---|---|---|
| 0 | 0.23002 | 5.07258 | -0.276061 | 0.832444 | -0.377866 | 0.480322 | benign |
| 1 | 0.155491 | -0.16939 | 0.670652 | -0.859553 | -0.377866 | -0.945723 | benign |
4.2 AnoGANbenchmark against Generative Models
AnoGAN is compared against two generative models for outlier detection, namely the Gaussian Mixture Model (GMM), a parametric model, and Kernel Density Estimation (KDE), a non-parametric model. Also, the extended Bhattacharyya AnoGAN is benchmarked against the original, residual loss AnoGAN described in ? (adapted to this dataset).
In KDE, the distribution of the data is being estimated using by placing kernel functions on each of the points, and then computing the contribution of each kernel to the probability density. Based on the prior assumption about the number of outliers to be expected in the dataset, n , the n lowest likelihood members of the distribution are being flagged as outliers.
In GMM, a mixture made up of a finite number of Gaussian distributions is being fit on the data. During evaluation, similar to the KDE case, a threshold is being imposed on the data. If the test candidate has a value below the threshold with respect to each of the Gaussian clusters, it is flagged as being an outlier.
In this implementation, the number of Gaussian clusters to consider is being parameterised.
For AnoGAN, the test dataset is grouped together in samples of 30 mammogram readings. The test groups were split between groups consisting of 100% clean data, and groups containing 100% anomalous data.
After anomaly training, the Bhattacharyya, discriminator and anomaly loss at convergence is being collected from each of the groups. A plot of these loss values can be seen in Figure 4.2
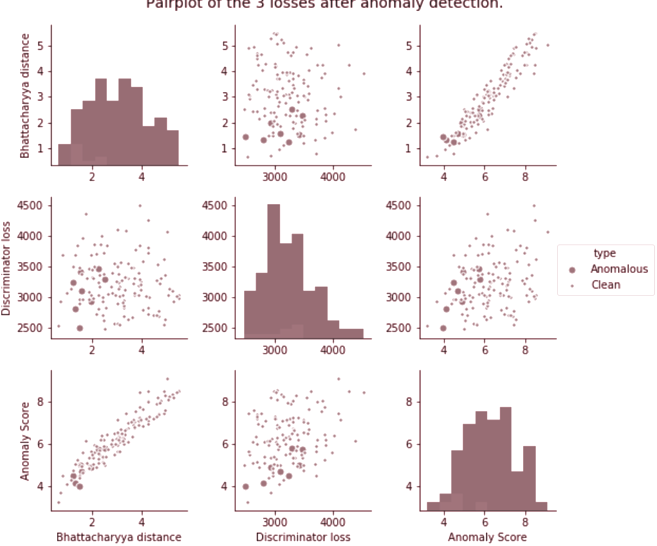
The bizarre observation that can be made in this situation is that the losses of anomalous samples have lower values than losses of clean samples. This is contrary to what was expected from this experiment.
Nevertheless, one success of this extended form of the AnoGAN outlier detection algorithm was increasing between-class separation.
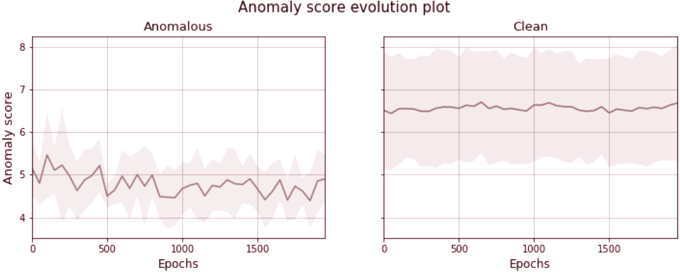
Investigating the evolution of the anomaly score across training for all test canditates, the anomaly score can be seen to not converge to a value much smaller value than the initial starting value. Figure 4.3 shows a time-series plot of the anoamly score across the whole outlier detection process.
Moving forward with this result, a KDE model is fitted on the anomaly score of the test candidates. As the test dataset includes 8 anomalous groups and 130 clean groups, a threshold on the likelihood is imposed at 0.062 ( 8 130 ).
| Accuracy | Error rate | Recall | Fallout | Precision | Prevalence | |
|---|---|---|---|---|---|---|
| KDE | 0.966 | 0.034 | 0.273 | 0.017 | 0.272 | 0.023 |
| GMM | 0.977 | 0.023 | 0 | 0 | 0 | 0 |
| AnoGAN | 0.888 | 0.112 | 0.125 | 0.063 | 0.111 | 0.067 |
| Res. AnoGAN | 0.893 | 0.107 | 0.527 | 0.061 | 0.525 | 0.113 |
Though all four models have very high accuracies, since accuracy is computed as: the high degree of accuracy of all three models is due to the fact that outliers make a very small proportion of the dataset (1.43% for test set of KDE/GMM/Residual AnoGAN and 5.97% for Bhattacharyya AnoGAN test set).
However, by looking at the Recall (true positives against actual positives), each model’s performance can be correctly judged.
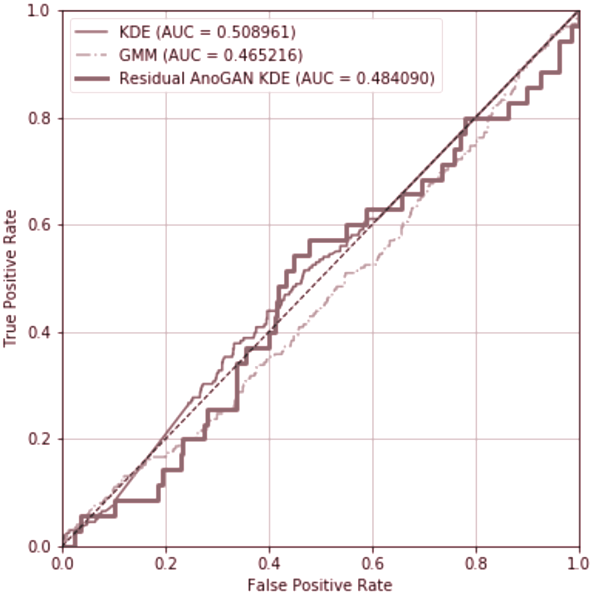
From the beginning, it is clear that the Residual AnoGAN model outperforms all other models, correctly identifying more than half of the outliers in the dataset.
The performance of Residual AnoGAN can be attributed to the much improved class separation that it achieves by mapping anomalies to a high anomaly score. This can be observed in figure
ROC Curve for Generative Models
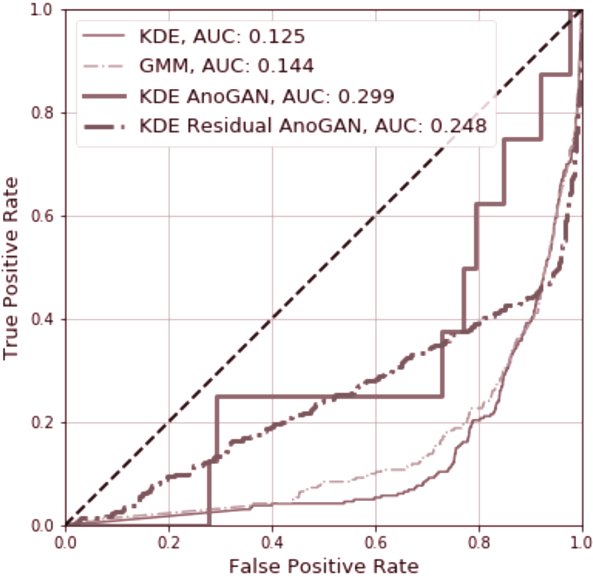
On the other hand, from the Receiver-Operating Characteritic curve, it can be observed that the extended AnoGAN model does have a better True Positive to False Positive ratio than all other models, judged by it’s AUC score.
After running this evaluation, the hypothesis can be safely rejected, justified by the significant discrepancy in Recall values between the extended Bhattacharyya AnoGAN model and the other models that were investigated.
Chapter 5 - Future Work
5.1 Latent space smoothing
Section 3.2.1.2 detailed how the process of outlier detection using GANs can be negatively affected by a non-smooth latent space of the generator.
In the backpropagation algorithm that finds a latent space representation for the test candidate, this can lead to generated images that look similar to anomalous images, thus leading to false negative results during the anomaly detection process.
One way to overcome this issue is to smooth out the latent space of the generator.
While this is not easily possible with a standard GAN, because the generator uses random noise as input, other techniques might be able to help with the smoothing of the latent space.
One such technique, detailed in Makhzani et al. (2015), uses a generator-discriminator adversarial pair in conjunction with an Autoencoder to impose a prior distribution on the latent space of the model (Figure 5.1).
5.2 Fully-unsupervised anomaly detection
Finding anomalies using AnoGAN involves applying a generative model on the losses of the test candidate, and thresholding the lowest likelihood candidates by using a prior probability of outliers existing in the dataset.
An interesting extension to this model could come from unsupervised GAN training using training data that contains a small proportion of outliers. In some experiments, I have found that adding a small amount of outlier images to the training of an GAN on MNIST did not affect the output of the generator adversely.

This could mean that the generator learns to map the most important features of the training data distribution. If this is the case, the AnoGAN model described in this project could still be used for identifying outliers without the need of training a GAN on strictly outlier-free data.
Chapter 6 - Conclusion
The work carried on in this project has investiged the use of Generative Adversarial Networks for training generative models to learn complex data distributions in an adversarial context, as well as representing complex high-dimensional data in a lower dimensional latent space embedding.
By exploiting a GAN’s ability to generate data from a latent space, this project has shown how the absence of a latent space embedding for a test candidate can be interpreted as the presence of an outlier.
Despite promising results on Computer Vision and Medical Imaging tasks, further work needs to be carried out to create an accurate, generic and robust GAN-based outlier detection model.
Appendix A - Model Hyperparameters
1-dimensional Gaussian experiment
Generator Network
The generator network was built as a Multilayer Perceptron with one hidden layer. Input layer width: 100; Activation: ReLU
Hidden layer width:
200; Activation:
Sigmoid
Output layer width:
100 Activation:
Hyperbolic Tangent
For optimisation, we used Adam as an optimizer, with a learning rate of 0 0002 .
The discriminator network was built as a Multilayer Perceptron with one hidden layer. Input layer width: 100; Activation: ReLU
Hidden layer width:
200; Activation:
Sigmoid
Output layer width:
100 Activation:
Hyperbolic Tangent
For optimisation, we used Adam as an optimizer, with a learning rate of 0 0002 .
Wine Quality experiment
The generator network was built as a Multilayer Perceptron with one hidden layer. Input layer width: 200; Activation: ReLU
Hidden layer width:
400; Activation:
ReLU
Output layer width:
200 Activation:
Sigmoid
Output layer width:
11 Activation:
Linear
For optimisation, we used Adam as an optimizer, with a learning rate of 0 0002 .
The discriminator network was built as a Multilayer Perceptron with one hidden layer. Input layer width: 200; Activation: Leaky
ReLU
Hidden layer width:
100; Activation:
Leaky ReLU
Output layer width:
50 Activation:
Leaky ReLU
Output layer width:
1 Activation:
Sigmoid
For optimisation, we used Adam as an optimizer, with a learning rate of 0 0002 and a beta1 value 0 9. . .
We added dropout with rate of 0.5 to all layers of both discriminator and generator.
Appendix B - Tensorflow Implementations
Appendix C - Convolutional Arithmetics
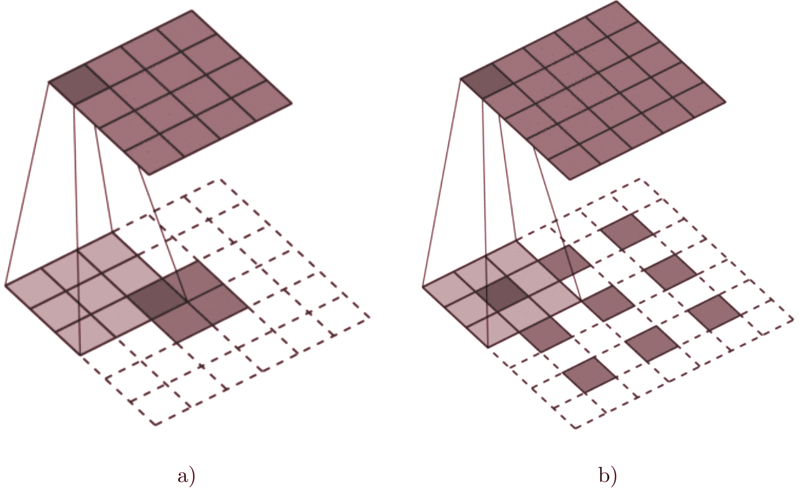
Figure C.1: Transposed Convolutional layer arithmetics. a) Transposed Convolution, no stride, no padding. b) Transposed Convlution, stride 2, padding valid. Figure adapted from Dumoulin and Visin (2016).
Appendix D - Dataset description
D.1 Wine quality dataset
The wine quality dataset presented in Cortez et al. (2009) is made up of red and white wines from the Portuguese ‘Vinho Verde’ collection. It is made up of 1599 red and 4898 white wine instances.
Input variables (based on physicochemical tests):
| Column No. | Attribute |
|---|---|
| 1 | fixed acidity |
| 2 | volatile acidity |
| 3 | citric acid |
| 4 | residual sugar |
| 5 | chlorides |
| 6 | free sulfur dioxide |
| 7 | total sulfur dioxide |
| 8 | density |
| 9 | pH |
| 10 | sulphates |
| 11 | alcohol |
Output variable (based on sensory data):
| Column No. | Attribute |
|---|---|
| 12 | quality (score between 0 and 10) |
Bibliography
Mart’ ın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viegas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. 2016. ISSN 0270-6474.
Martin Arjovsky, Soumith Chintala, and L’on Bottou. e Wasserstein GAN. 2017. ISSN 1701.07875.
A. Bhattacharyya. On a Measure of Divergence between Two Multinomial Populations, 1946. ISSN 00364452.
Paulo Cortez, Ant’nio Cerdeira, Fernando Almeida, Telmo Matos, o and Jos’ e Reis. Modeling wine preferences by data mining from physicochemical properties. Decision Support Systems , 47(4):547553, 2009. ISSN 01679236.
Julien Despois. Latent space visualization Deep Learning bits #2, 2017.
Drleft. Comparison of 1D histogram and KDE, 2010.
Vincent Dumoulin and Francesco Visin. A guide to convolution arithmetic for deep learning. ArXiv e-prints , 2016.
Al Gharakhanian. Generative Adversarial Networks Hot Topic in Machine Learning.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Nets. Advances in Neural Information Processing Systems 27 , pages 2672-2680, 2014. ISSN 10495258.
Diederik P Kingma and Jimmy Lei Ba. A METHOD FOR STOCHASTIC OPTIMIZATION. pages 1-15, 2015.
Y. LeCun, C. Cortes, and C.J. Burges. The MNIST Database of Handwritten Digits. http://yann.lecun.com/exdb/mnist/ , 2010.
Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, and Brendan Frey. Adversarial Autoencoders. 2015.
Karl Pearson. On lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science , 2(11):559-572, nov 1901.
Marco A.F. Pimentel, David A. Clifton, Lei Clifton, and Lionel Tarassenko. A review of novelty detection, 2014. ISSN 01651684.
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. nov 2015.
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision , 115(3):211-252, dec 2015. ISSN 15731405.
Thomas Schlegl, Philipp Seebck, Sebastian M. Waldstein, Ursula o Schmidt-Erfurth, and Georg Langs. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. mar 2017.
Laurens Van Der Maaten and Geoffrey Hinton. Visualizing Data using t-SNE. Journal of Machine Learning Research , 9:2579-2605, 2008.
Kevin S. Woods, Christopher C. Doss, Kevin W. Bowyer, Jeffrey L. Solka, Carey E. Priebe, and W. Philip Kegelmeyer Jr. Comparative evaluation of pattern recognition techniques for detection of microcalcifications in mammography. International Journal of Pattern Recognition and Artificial Intelligence , 7(06):1417 - 1436, dec 1993. ISSN 0218-0014.