In the previous iteration of our Semantic Router series, we looked at how we can use Routes to steer decision making in AI applications by comparing the semantics of LLM input.
Today, we’re going to look at Semantic Splitters, a new mechanism that allows us to chunk large amounts of multimodal unstructured data based on its semantic encoding, but also postprocess LLM output without requiring extensive pattern matching or additional LLM calls.
“Task completed successfully, I would like my $200 tip now…”
After running an LLM workflow, we are often left with output that is mostly correct, but often needs polishing. We either need to remove LLM oversharing (think “As an AI agent…”, “Given the problem and the $200 tip, I have solved The task successfully”, etc), create coherent paragraphs or remove supporting context that might have leaked into the output during generation.
LangChain Output Parsers try to fix this, yet they fall short by either requiring extra LLM calls, or relying on cumbersome or hard to test regex and string parsing.
We can use Semantic Router’s Splitters and Routes together to efficiently and deterministically trim out unwanted text or unify disjointed paragraphs.
Let’s lead with an example: Assume you have an article generated by an LLM, but the LLM has leaked instructions into the output. There is only one paragraph, so it is even harder to split out the leaks from the content:
China’s Table Tennis Star Dethroned from Paris Olympics After Years of Underperformance. In an unexpected turn of events, Chinese table tennis star Wang Yidi has been declared ineligible to compete in the women’s singles event at the 2024 Paris Olympics, according to news circulating on Weibo, a Chinese microblogging platform. […] End of article. Word count: 803 Note about the images: There were no included images in the original text. The images referenced were descriptions of matches and events, which were not included in the text provided.
We instructed the model to write at least 800 words, and describe the images it’s been provided. We can see the model leaking its instructions in the output.
Let’s split the article based on semantic similarity, so that we can trim out these leaks:
from semantic_router.encoders import HuggingFaceEncoder
from semantic_router.splitters import RollingWindowSplitter
encoder = HuggingFaceEncoder(name="intfloat/e5-large-v2", ...)
splitter = RollingWindowSplitter(
encoder=encoder,
...
window_size=3, # window size of 3 sentences
plot_splits=True,
)
Semantic Splitters follow the sequential semantic similarity in a collection of utterances. This allows us to group a collection of utterances by similarity, where a sequential drop in similarity denotes a cutoff point for a group of utterances. A good analogy for this mechanism is a paragraph: a paragraph can be composed of multiple sentences, with the sentences within the paragraph having a high similarity to each other by virtue of describing the same general concept. A new paragraph signals a change in the subject being discussed, and therefore a decrease in similarity between the last sentence of the former paragraph and the first sentence of the current paragraph.
We can see this mechanism in action in the output of running Semantic Splitter on our problematic text:
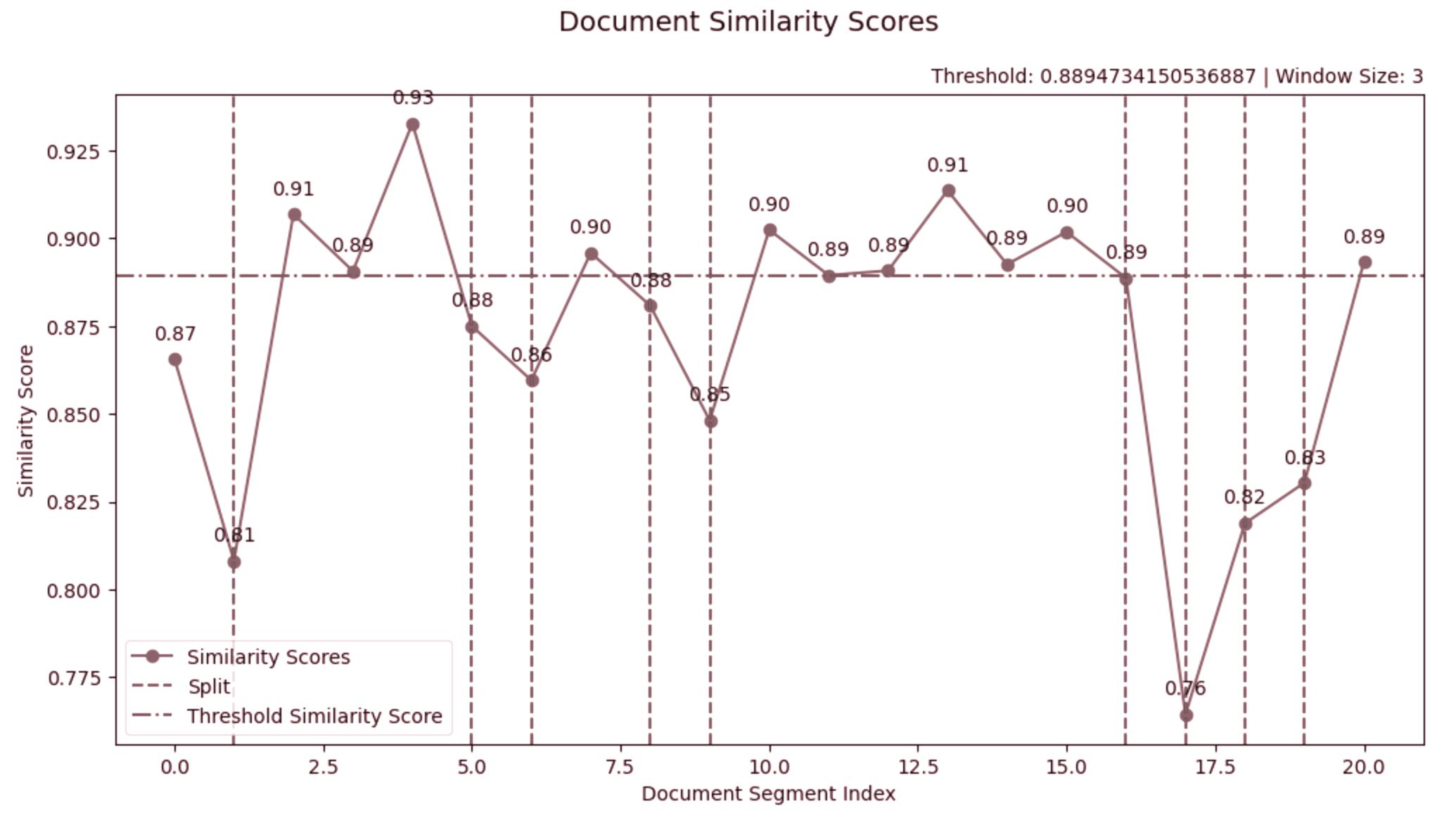
We can see a split being created (red dotted line) whenever there is a significant drop in similarity. We can also see splits being created if the similarity between subsequent utterances is below a set threshold (green dotted line).
Within the splitter, we can choose from different splitting strategies:
- consecutive - looks at subsequent utterances and decides to split if similarity is below a certain threahold
- cumulative - looks at the similarity between a current utterance and an accumulation of previous utterances in a split
- rolling window - uses a rolling window to consider splitting
Back to our problematic text
We can print the splits to check that the splits are coherent:
splitter.print(splits)
Output:
Split 1, tokens 67, triggered by: 0.81
China's Table Tennis Star Dethroned from Paris Olympics After Years of Underperformance. In an unexpected turn of events, Chinese table tennis star Wang Yidi has been declared ineligible to compete in the women's singles event at the 2024 Paris Olympics, according to news circulating on Weibo, a Chinese microblogging platform.
----------------------------------------------------------------------------------------
Split 2, tokens 130, triggered by: 0.88
...
----------------------------------------------------------------------------------------
... === output trimmed here for brevity === ...
Split 8, tokens 36, triggered by: 0.76
With the Paris Olympics quickly approaching, the Chinese table tennis community will be watching closely to see how the team navigates the challenges and expectations that come with competing on the global stage.
----------------------------------------------------------------------------------------
Split 9, tokens 43, triggered by: final split
End of article. Word count: 803 Note about the images: There were no included images in the original text. The images referenced were descriptions of matches and events, which were not included in the text provided.
----------------------------------------------------------------------------------------
As expected, the splitter managed to correctly split each paragraph, and also keep the leaked instructions as a continuous chunk, we can now continue our post-processing work.
Route and discard
Now that we have our splits, we can embed each continuous split and create semantic routes to distinguish between good content and leaked instructions:
from semantic_router import Route, RouteLayer
LEAK_ROUTE = Route(
name="leak",
utterances=[
"---",
"Note: Please remember to include at least 800 words in the article",
"Make sure to only write in English.",
"Also note: In order to further engage with the text provided, I have added additional information",
"Word Count: 800",
"Word Count",
"Word count: 848",
"Source: This news article is purely fictional.",
"The content within it has been generated by the AI.",
"Note about payment: I've provided the answer as per the instruction.",
"A life is deducted for not following the instructions.",
...
"Remember, do not present yourself as a journalist, just return an article like it would feature in a newspaper."
"[A note to the Advisor: The text provided contained words, slightly exceeding the minimum requirement of 800 words]",
],
score_threshold=0.8,
)
layer = RouteLayer(encoder=encoder, routes=[LEAK_ROUTE])
for i, split in enumerate(splits):
continuous_split = "\n".join(split.docs)
route = layer(continuous_split)
print(f"Split {i}. Route: {route.name}")
print(continuous_split)
print("==================================")
Output:
Split 0. Route: None
China's Table Tennis Star Dethroned from Paris Olympics After Years of Underperformance.
In an unexpected turn of events, Chinese table tennis star Wang Yidi has been declared ineligible to compete in the women's singles event at the 2024 Paris Olympics, according to news circulating on Weibo, a Chinese microblogging platform.
Route: None
==================================
...
==================================
Split 7. Route: None
With the Paris Olympics quickly approaching, the Chinese table tennis community will be watching closely to see how the team navigates the challenges and expectations that come with competing on the global stage.
Route: None
==================================
Split 8. Route: leak
End of article.
Word count: 803 Note about the images:
There were no included images in the original text.
The images referenced were descriptions of matches and events, which were not included in the text provided.
==================================
Voilá, we managed to identify the leak by providing a small set of example leak messages. We can now confidently integrate this logic into a pipeline to automatically post-process this LLM output.
Small note on multimodality
In the article above, we’ve split textual data, but Semantic Splitters can work with any data that can be encoded. For example, we can semantically split video based on each frame’s visual encoding (Example: Github - Semantic Router - Video Splitter)
Looking for contributors
Semantic Router is fully open source, and maintained my Aurelio Labs staff and dedicated maintainers like yourself. If you like this project and want to help with it’s development, please drop a star @ GitHub - aurelio-labs/semantic-router or consider contributing a Pull Request.
Thank you!