RAG or Retrieval-Augmented Generation is the de-facto standard for information retrieval in LLM-assisted applications such as chatbots and “AI” assistants. The TL;DR of RAG is that, by adding grounded context to an LLM generation, you can guide said LLM and significantly reduce the chance of hallucinations.
The issue, however, is that LLMs have finite context lengths, meaning that we need to be picky about what we in-scope as the context for the LLM generation.
RAG 101
An oversimplification of a typical RAG pipeline are the two stages below:
- offline document processing where disparate documents are broken down into semantically-coherent chunks, embedded into a hyperdimensional vector space and stored into a data store
- online retrieval where a live user query is similarly embedded into hyperdimensional space, and compared using similarity metrics to the collection of processed documents mentioned above
Comparing and retrieving only the relevant documents for the user’s query allows us to provide a grounded context to the LLM while not exceeding its context length.
Hallucinations are a precision problem, missing relevant content however, is a recall one
In Statistics, a confusion matrix can be used to evaluate a classification systems’ performance:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive | False Negative |
| Actual Negative | False Positive | True Negative |
By trying to avoid hallucinations, we are aiming for a precise retrieval and generation system, meaning that if we retrieve a document, that document is relevant for the query at hand, and the LLM generation follows that ground context closely. Therefore, out of all the documents retrieved, we want to maximise the ones that are relevant to our query, and minimise the ones that are retrieved, but are not relevant.
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive | False Negative |
| Actual Negative | False Positive | True Negative |
Can you see what the process above misses though?
While the system is very precise and doesn’t hallucinate or retrieve irrelevant information, by pursuing a hallucination-free system, relevant information might slip through the retrieval system and never even be considered by the LLM in the first place. This second metric that evaluates how many of the total, actually relevant documents in our data store are retrieved is referred to as recall.
Higher precision means that an algorithm returns more relevant results than irrelevant ones, and high recall means that an algorithm returns most of the relevant results (whether or not irrelevant ones are also returned).
Going back to our confusion matrix, high recall would look like this, high true positives, low false negatives:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive | False Negative |
| Actual Negative | False Positive | True Negative |
An example to illustrate
Let’s really solidify this concept by using an example of a Wikipedia-based vector database and a user query for “European capitals on the Dabube” as an oversimplification. Let’s be even more ridiculous to illustrate this example and just say that, we’ll only retrieve the top 3 most relevant documents for the query:
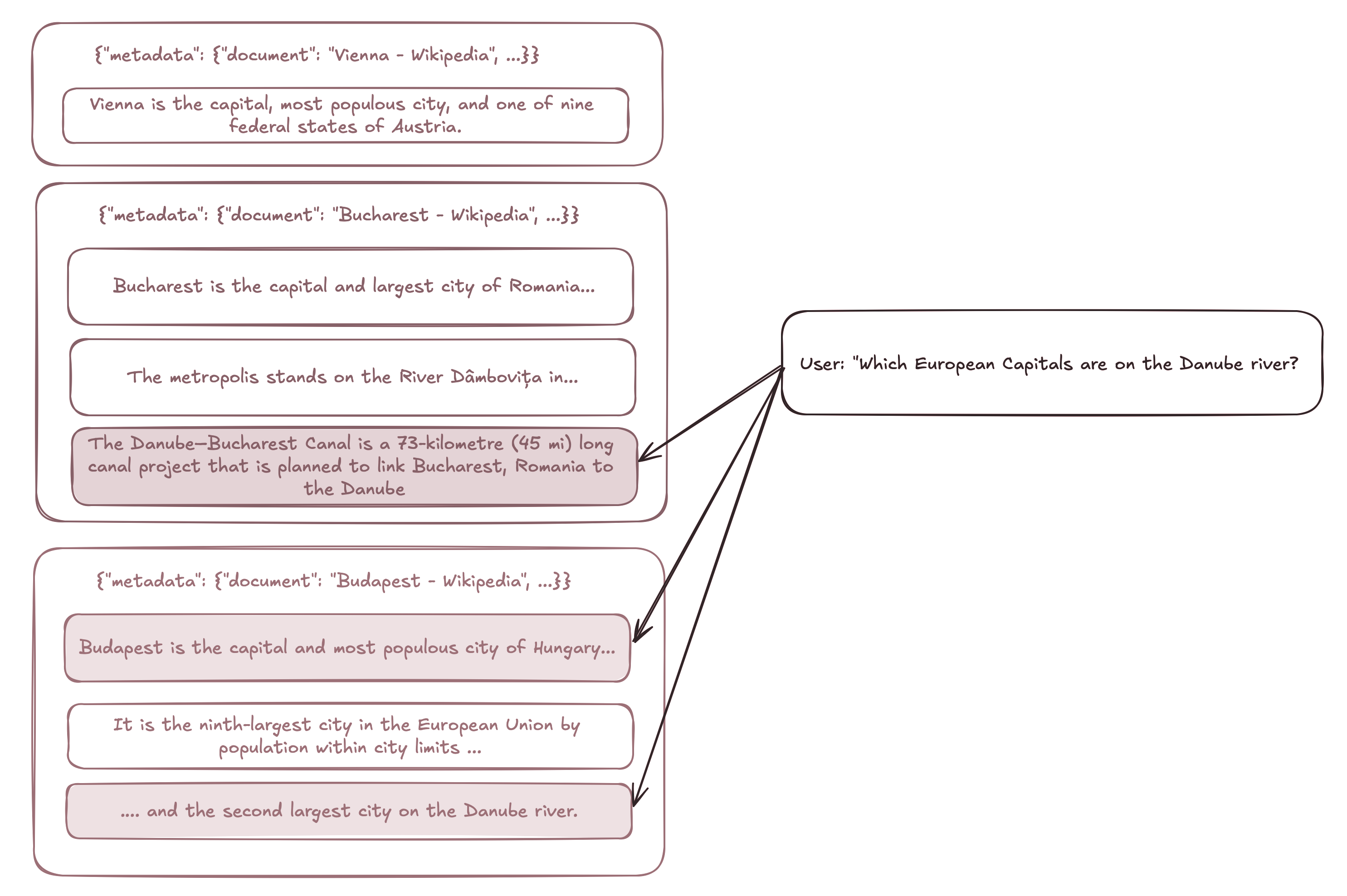
In this case, Vienna, a European capital on the Danube, is not considered relevant for in-scoping into the LLM generation context. However, Bucharest, a European capital not on the Danube is relevant, as the query “Which European capitals are on the Danube river” is more semantically similar with “The Danube-Bucharest Canal is a 73-kilometre…” than “Vienna is the capital, most populous city, and one of the nine federal states of Austria”.

This is obviously a ridiculous toy example that wouldn’t even require document retrieval, as the information is likely already baked into the LLM.
However…
When building RAG systems based on data that is not expected to already be built into the model (proprietary data comes to mind), it is very important to take steps to handle the case when our RAG system produces False Negatives.
It would be catastrophic if an LLM-powered sales assistant would fail to retrieve relevant leads, or even worse if a LLM-powered diagnostic system would do the same.
Quick fixes that come to mind
- perform Semantic Chunking, by joining semantically coherent documents into single chunks (aurelio-labs/semantic-chunkers can help here)
- use two-stage retrieval, by tackling the recall issue using a higher
top_kvalue to retrieve more documents from the Vector DB initially, and then using a Cross Encoder to rerank documents and improve precision - for unstrured data such as PDFs, consider using vision models to embed and retrieve image patches directly (see ColPali)
A closing rant on UI/UX in the LLM age…
As AI makes its way into more and more corners of our lives, the recall problem really keeps me up at night. We’ve talked at lengths about the lack of explainability in the Deep Learning space, but as the multi-turn chat interface has become the standard of interacting with LLMs, I think we need to depart from “this is magic” UX and surface more of the stages (whether it’s RAG or Chain of Thought) to the end user, to increase the confidence in LLM generations.