Installing NVIDIA drivers is pain. Pure pain. Then throw in Auto-Scaling Groups, MIME-type multipart uploads for bootstrap scripts and NVIDIA specific containerd configuration and you might as well call it a day and sign up for Replicate or HuggingFace’s Inference endpoints and pay a hefty premium.
But first, why?
Setting aside cost savings on on-demand instances (AWS A10G instances are 30% cheaper than the same instance on HuggingFace), even bigger cost savings leveraging Spot instances in your K8s node pools, even bigger savings on S3 egress costs (if you roll your own LLMs).
Integrating your inference endpoints into your existing, mature, infrastructure is a no brainer. You already have your secret store, your complex RBAC policies, telemetry, CI/CD, and, in the case of compliance, sometimes the need for fully-private network traffic.
While a pre-warmed endpoint to hammer with prompts seems lovely, you can roll your own with a bit of elbow grease.
The architecture of our build
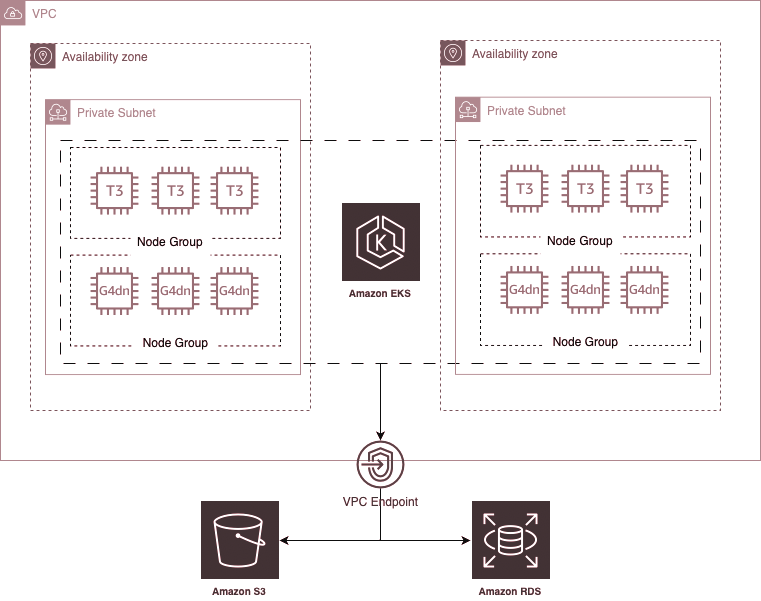
We’re going to create an EKS cluster with two node pools: 1) the default node pool for scheduling non-GPU workloads, and the 2nd with GPU-instances (I chose the Telsa T4-enabled g4dn.xlarge for this example) solely for GPU workloads (more on this later).
Opting for a fully private cluster takes away the headache of security groups for everything besides Ingress into your cluster, and I like that.
And instead of VPC-peering, where we soon end up with CIDR conflicts, we open direct connections to services we need (RDS, …).
I use Terraform to lay out all the dependencies logically as code, but I will skip this code here as there’s countless “Terraform EKS Cluster” tutorials out there.
The GPU Nodes
There are two requirements we need to satisfy to have a successful GPU-enabled node that can run container workloads:
- Have the CUDA drivers, together with NVIDIA’s nvidia-container-toolkit and nvidia-container-runtime
- Run a bootstrap script which registers our EC2 Node in the ASG with the EKS cluster.
Luckily for us, step 1 is solved by AWS, with their custom GPU-optimised AMI image. I’ve tried to install CUDA drivers on Amazon Linux 2 OS and it’s not fun, so this is very welcome.
For step 2, we’ll have to write a custom bootstrap script:
#!/bin/bash
/etc/eks/bootstrap.sh ${cluster_name} \
--use-max-pods false --cni-prefix-delegation-enabled \
--kubelet-extra-args '--max-pods=110' \
--container-runtime containerd
Which, in Terraform, we can attach to the custom launch template as so:
const EKS_OPTIMIZED_GPU_AMI = "ami-0dafd3a1dc43781f7";
const bootstrapEksScript = new TerraformAsset(
scope,
"bootstrap-eks-script",
{
path: path.join(process.cwd(), "customized_bootstrap.sh"),
type: AssetType.FILE,
}
);
const launchTemplate = new LaunchTemplate(scope, "launch-template", {
...
imageId: EKS_OPTIMIZED_GPU_AMI,
userData: Fn.base64encode(
Fn.templatefile(bootstrapEksScript.path, { cluster_name: clusterName })
),
...
});
...
new EksNodeGroup(scope, "NodeGroup", {
...
launchTemplate: launchTemplate,
...
taint: [
{
key: "nvidia.com/gpu",
effect: "NO_SCHEDULE"
}
]
});
After you’ve configured and tainted and deployed your GPU nodes, they should join your cluster.
Before you can schedule GPU workloads on your cluster, you will have to add an NVIDIA DaemonSet plugin which allows you to do so:
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
You should then be able to test you can schedule GPU workloads.
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
kubectl apply -f <file_above>.yaml
Note: because
nvidia.com/gpuresources map directly to GPU cards, therefore, sometimes we can only allocate 1 workload per GPU-instance. This is the reason we’ve split our Node Groups into GPU and non-GPU, and tainted the GPU node to prevent non-GPU workloads from scheduling there
And you should see this result:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Stream closed OF for default/test-gpu-fd9d97f47-h9t2m (cuda-container)
HuggingFace’s Text Generation Inference
The legends at HuggingFace open sourced (though bearing a controversial license) the webservers that power their Inference endpoints, namely huggingface/text-generation-inference, and we’ll be making heavy use of those for a bunch of reasons:
- Out-of-the box Prometheus metrics (
/metricsendpoint) - Pull any model you have access to from HuggingFace
- Flash Attention, Paged Attention, model-sharding between GPUs, and more ways to squeeze performance out of your expensive cards
- Quantisation via
bitsandbytesandGPT-Q - Maintained Docker image
- … and way way more features
At the moment, this webserver works with newer NVIDIA cards like the A100, H100, T4-series, but it’s capabilities are expanding.
Let’s deploy a simple codellama/CodeLlama-7b-hf model to see how we go:
apiVersion: apps/v1
kind: Deployment
metadata:
name: codellama
namespace: tgi
spec:
replicas: 1
selector:
matchLabels:
app: codellama
tier: codellama
template:
metadata:
labels:
app: codellama
tier: codellama
spec:
nodeSelector:
eks/node-type: gpu
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
volumes:
- name: shm
emptyDir: {}
- name: data
emptyDir: {}
containers:
- name: text-generation-inference
image: ghcr.io/huggingface/text-generation-inference
:sha-7c2e0af
args: ["--model-id", "codellama/CodeLlama-7b-hf", "--num-shard", "1", "--quantize", "bitsandbytes"]
ports:
- containerPort: 80
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: data
mountPath: /data
resources:
limits:
nvidia.com/gpu: 1
memory: 10Gi
cpu: 1000m
requests:
memory: 1Gi
cpu: 10m
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
name: codellama-service
namespace: tgi
labels:
app: codellama
spec:
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
selector:
app: codellama
Finally, we’re all set in for some inference:
printf (curl -XPOST http://codellama-service.tgi/generate \
-d '{"inputs": "Fibonacci numbers in Python", "parameters": {"max new tokens":200}}' \
-H 'Content-Type: application/json' | jq ".generated_text")
### Fibonacci numbers
The Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci seq uence, and characterized by the fact that every number after the first two is the sum of the two preceding ones:
1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181,
### Fibonacci numbers in Python
The Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci seq uence, and characterized by the fact that every number after the first two is the sum of the two preceding"a
And pretty soon enough with larger models, we’ll get our first:
torch.cuda.OutOfMemoryError: CUDA out of memory.
Monitoring
Alright, so we blew right through our GPU memory budget, but why? How can we check the memory and utilization of the GPUs we’ve just deployed?
Well, NVIDIA comes to the rescue once again, with a Prometheus-enabled metrics exporter, packaged as a Helm chart:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm install nvidia-gpu-operator nvidia/gpu-operator -n dcgm-exporter --create-namespace --set driver.enabled=false --set toolkit.enabled=false
Now in your Prometheus config (here, the Prometheus community Helm chart), you should add a custom job for the NVIDIA DCGM metrics
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts/
helm inspect values prometheus-community/kube-prometheus-stack > values.yaml
--- values.yaml ---
...
additionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- dcgm-exporter # this has to be the same namespace as
# your nvidia/gpu-operator deployment
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
...
And voila, we’ve got all of our GPU metrics in Grafana now, and it seems that a Tesla T4 with 16GB of RAM can’t handle the GPTQ-quantised Llama2-7B weights.
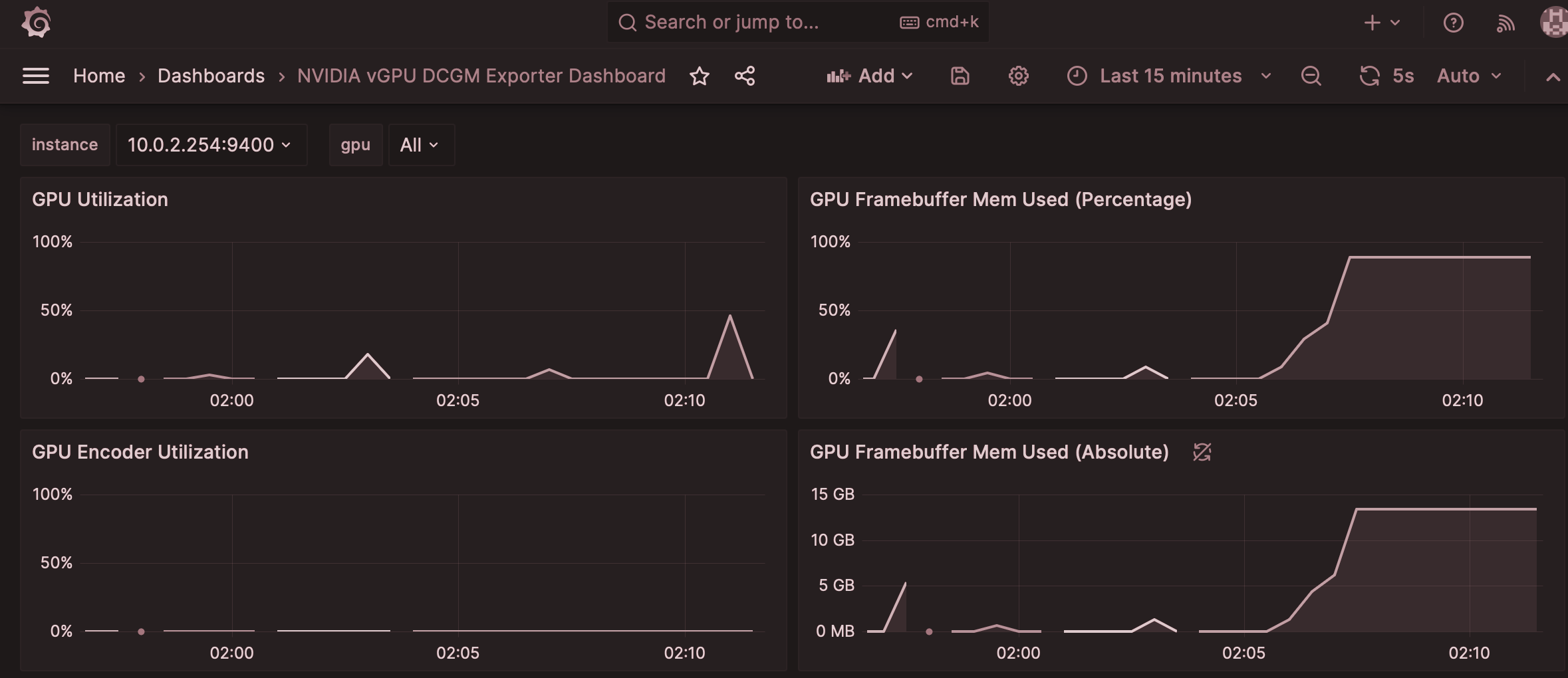
Closing Thoughts
Compared to the public offering from services such as Replicate, HuggingFace, MosaicML, setting up your own infra, adhering to your own SLAs is definitely not easy, but it’s not insurmountable.
We’re standing on the shoulders of giants, being able to share Terraform snippets, Helm charts, etc. to quickly provision the infrastructure we need.
The biggest benefit to rolling your own Inference infrastructure is definitely the flexibility, and being able to swap hardware in and out to your requirements. Which brings me to…
AWS Inferentia
As you saw above, a 16GB card is barely able to trundle along with a quantised version of a 7B parameter LLM, so what do we do now? Do we just throw our credit cards out the window for some A100 cards? Well, yes, and no…
AWS came out with these instances that were purpose built for Inference, sporting really large GPU memories (the smallest inf2.xlarge instance has 1 Inferentia2 Accelerator with 32GB of Accelerator memory).
It is clear that today’s LLM tasks are bound by Accelerator memory, and these Inferentia instances offer a significant cost reduction to using NVIDIA-based instances.
For comparison:
| Instance Type | Accelerator Type | Accelerator Memory | On-demand Pricing / hr |
|---|---|---|---|
| inf2.xlarge | AWS Inferentia2 | 32GB | $0.76 |
| g5.xlarge | NVIDIA A10G | 24GB | $1.006 |
| inf2.48xlarge | AWS Inferentia2 | 384GB | $12.98 |
| p4d.24xlarge | NVIDIA A100 | 320GB | $32.77 |
At the moment TGI does not support AWS Inferentia (inf1, inf2) type instances. You should keep an eye on this, as these inference-specific instance types will be a huge cost saver in terms of GPU-MEM / $.
Thank you
If you’ve made it this far, thank you so much! This was a long and arduous blog post. Wishing you the best in your LLM Inference journeys.