Creating pipelines of LLM-based transformations is a standard in increasingly many data pipelines. Given the rise of tools such as LangChain, you can really squeeze more out of your LLM than just prompt engineering endlessly.
And while I have my own beef with LangChain (and I’m not the only one), I wanted to write a blog to detail how you can use industry standard, tried-and-tested Data Engineering tools to achieve a robust LLM pipeline you can trust, inspect and rely on.
In this post, I will be focusing on Dagster as a data orchestration and data pipeline observability tool, and how it can fit into your LLM workflow.
We will build a simple toy example which fetches the top HackerNews stories, scrapes the pages for text content, and summarises the pages using LLaMa 2. Let’s dive in!
Dagster - your data pipeline’s best friend
Dagster is a data orchestration tool that aims to get you focused on writing application code as declaratively as possible, instead of your time configuring graphs of operations (I’m looking at you, Airflow).
It is surprisingly easy to get started with a local development environment, and so is going from development to production.
Let’s start by installing Dagster and Dagit. I will be using Poetry for managing Python dependencies and virtual environments, but tools such as virtualenv work as well.
$ poetry config virtualenvs.in-project true --local
...
$ poetry init
...
$ poetry add dagster dagit
...
Then go ahead and create a new project with the following file structure:
└── src
├── __init__.py
├── assets.py
├── ops.py
├── prompts.py
└── resources.py
Assets
A core unit in Dagster’s concepts is the Software-defined asset. This unit is meant to represent a storage-persisted object such as a database table, blob in storage or just a file on a file system. Think about this asset as the instructions that need to be executed to compute a DB table or file.
Our first asset be a collection of IDs representing the top HackerNews stories. In your src/assets.py file:
import requests
from dagster import asset
HN_TOPSTORIES_URL = "https://hacker-news.firebaseio.com/v0/topstories.json"
@asset
def topstory_ids():
top_new_story_ids = requests.get(HN_TOPSTORIES_URL).json()
return top_new_story_ids
Annotating a Python function with @asset tells Dagster that this function is an asset, but it also allows you to chain assets together by passing an asset’s name as another asset’s positional argument. To illustrate this, let’s grab each of the topstories from HN based on their ID:
HN_ITEM_URL = "https://hacker-news.firebaseio.com/v0/item/{item_id}.json"
@asset
def topstories(topstory_ids):
results = []
for item_id in topstory_ids:
item = requests.get(HN_ITEM_URL.format(item_id=item_id)).json()
results.append(item)
return results
The result of topstory_ids gets passeed to the topstories asset automatically by Dagster. Now let’s look at how this looks in Dagit, Dagster’s UI.
poetry run dagit -f src/assets.py -d . -p 3000

That’s great! Dagster automatically used the method naming to figure out the hierarchy in our DAG.
We’ve already fetched the top stories, now let’s grab their content for further analysis.
Ops & Graphs
Not every single operation you perform on your data will be persisted, and for this, Dagster has ops. These are simple units of computation that can be composed.
For instance, in our toy example, we can use an op to make an HTTP request to fetch the content of each of our top stories.
import requests
from bs4 import BeautifulSoup
@op
def get_page_text(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
return soup.get_page_text()
Now that we’ve defined how we want to fetch the page, let’s schedule it in our graph.
We could just loop over the list of item ids, however, let’s parallelise this operation, so that we can fetch webpages and summarise them in parallel.
First, we’ll have to use Dagster’s DynamicOutput, to allow us to return an arbitrary number of results from an operation.
...
@op(out=DynamicOut())
def _fan_out(topstories):
for i, topstory in enumerate(topstories):
yield DynamicOutput(
topstory.get("url"),
mapping_key=str(topstory.get("id", i))
)
fanned_topstories = _fan_out(topstories)
...
What we’ve just done is to “fan out” the list of topstories into individual topstory_id operations, on which we can apply map-reduce style operations.
For each of the DynamicOutputs, let’s apply the get_page_text operation we created above. For this, we will use the .map function:
topstories_text = fanned_topstories.map(get_page_text)
Now we can just chain these map operations to run summarisation on these texts. At this point, let’s just assume that we have a magical function called summarise_text that generates a summary for us.
topstories_summaries = topstories_text.map(summarise_text)
To finish, as with any standard map-reduce operation, we can collect all of our summaries together witha final op:
@op
def _process(topstories_collection):
return list(topstories_collection)
summaries = _process(topstories_summaries.collect())
Note: while it seems intuitive that we could just wrap the .collect() statement in a list, remember that we are dealing with Dagster primitives here, which could be scheduled on different machines, therefore, we need a final
opto collect everything together
Graph-backed assets
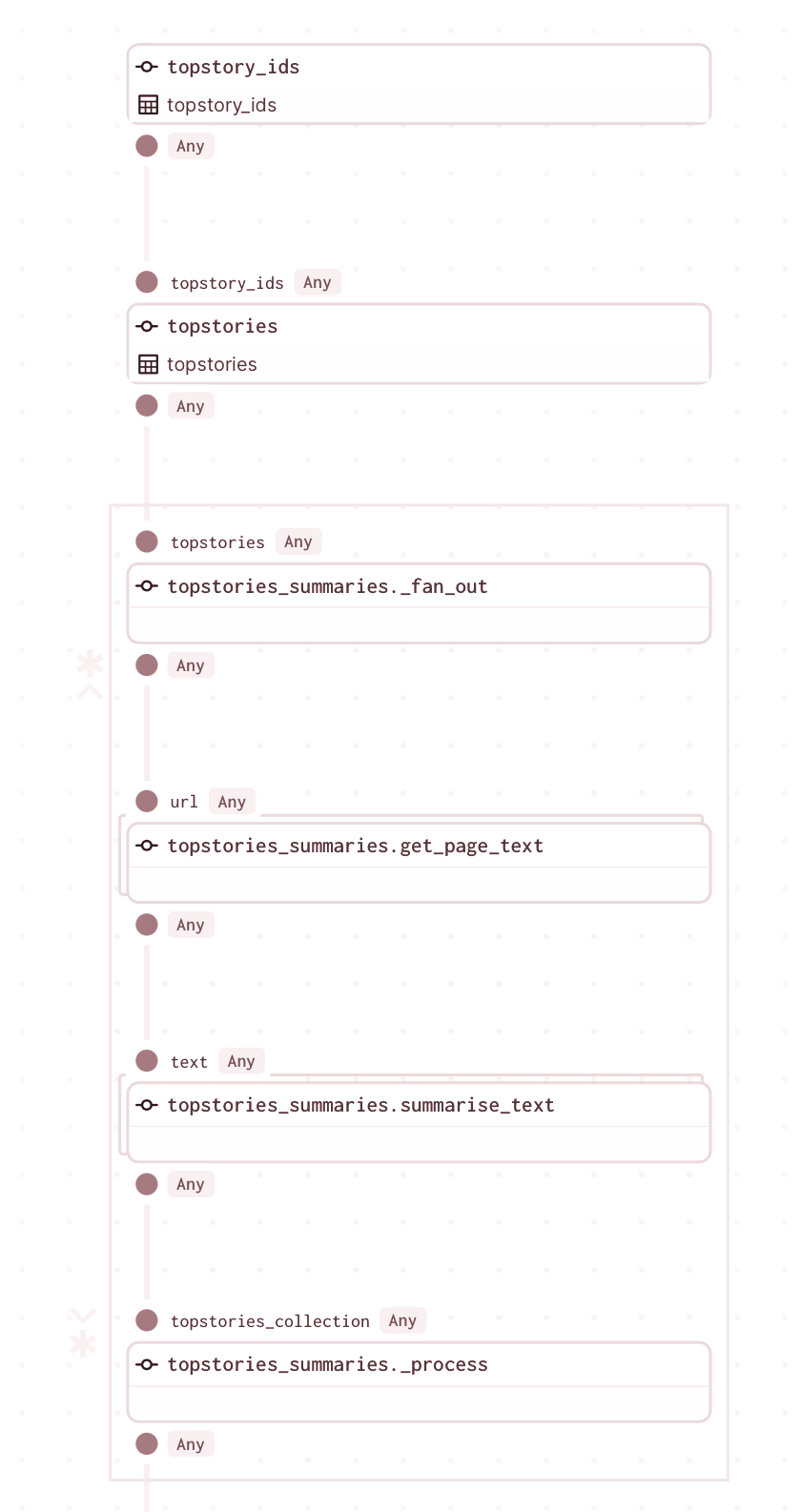
Now that we’ve created the map-reduce graph that will compute our summaries table, let’s go ahead and create an asset out of it. The good news is that Dagster includes a primitive called @graph_asset which can be used to convert a graph into an asset.
Taking the above compute, this is how the graph should look like:
@graph_asset
def topstories_summaries(topstories):
@op(out=DynamicOut())
def _fan_out(topstories):
for i, topstory in enumerate(topstories):
yield DynamicOutput(topstory.get("url"), mapping_key=str(topstory.get("id", i)))
@op
def _merge(topstories_collection):
return list(topstories_collection)
fanned_topstories = _fan_out(topstories)
topstories_text = fanned_topstories.map(get_page_text)
topstories_summaries = topstories_text.map(summarise_text)
summaries = _merge(topstories_summaries.collect())
return summaries
We can now see the resulting graph in Dagit now.
Observability
We want to be able to see the intra-pipeline asset results, and we can do so by attaching metadata when returning a result from an asset.
To do this, we are going to wrap that return value with an Output class, and specifying metadata, as such:
@asset
def topstories(topstory_ids):
...
return Output(
value=results,
metadata={
"num_records": len(results),
"preview": MetadataValue.json(results),
},
)
LLaMa - our muscle
Now that we have the building blocks in place, time to add the centerpiece of our pipeline, our LLM.
I’ve been using LLaMa-based LLMs for summarising Chinese-language content for Trending on Weibo, for fun and reduced cost (no need for GPT API keys). Now that Llama 2 is out, we’re going to use that here.
llama.cpp & llama-cpp-python
For this example, we are going to set up a separate HTTP server that will serve responses from a Llama model.
Why a separate server? When we move to deploy this to prod, we might want to use powerful GPU instances for Llama only, while the rest of the light HTTP requests to and from HackerNews can be handled by instances with less compute.
To prevent this article from overruning, I will provide some links to follow to get the Llama weights and the webserver running on your machine. These repositories each have instructions, and at the end, you should have a webserver serving traffic on port :8080.
C/C++ port of Llama, optimised for M1 Macbooks - ggerganov/llama.cpp
Llama2 weights - Meta website
Python bindings for llama.cpp & FastAPI web server - abetlen/llama-cpp-python
Alternatively, you can skip this and just use the llama13b-v2-chat endpoint from Replicate (at a small cost).
Resources
Dagster Resources are objects shared across implementations of multiple assets, ops, graphs, etc. They can be easily swapped in and out, mocked, and configured for development and production.
While we won’t go in depth into Resources here, you can read more about them in the Dagster documentation - Resources page.
Our Llama inference endpoint will be a Dagster resource, as we might use it in different places in the future. It will look like this:
import requests
import json
from typing import List, Optional
from dagster import ConfigurableResource
from src.prompts import SUMMARY_PROMPT_TEMPLATE
class LlamaResource(ConfigurableResource):
endpoint: Optional[str]
def _predict(self, prompt: str, stop: List[str], max_tokens: int):
data = {"prompt": prompt, "stop": stop, "max_tokens": max_tokens}
if not self.endpoint:
raise ValueError("You haven't specified an endpoint for your llama.cpp server")
response = requests.post(self.endpoint, headers={"Content-Type": "application/json"}, data=json.dumps(data))
return response.json()["choices"][0]["text"]
def summarise(self, text):
summary = self._predict(prompt=SUMMARY_PROMPT_TEMPLATE.format(text=text), stop=["\n"], max_tokens=500)
return summary
Now that we have our resource, it’s time to create our summarise_text function:
@op
def summarise_text(text, llama: LlamaResource):
summary = llama.summarise(text=text)
return summary
Here, our LlamaResource is being referenced, so Dagster knows it needs to inject it at runtime.
Scheduling
We want to run this job every hour, so let’s go ahead and create a schedule.
In the src/__init__.py file, go ahead and set up as follows:
import os
from dagster import AssetSelection, Definitions, define_asset_job, load_assets_from_modules, ScheduleDefinition
from src import assets
from src.resources import LlamaResource
# Load all our assets
all_assets = load_assets_from_modules([assets])
# Load our Llama resource
llama = LlamaResource(endpoint=os.getenv("LLAMA_CPP_ENDPOINT"))
# Define our HN job, which uses all the assets we've defined above
hackernews_job = define_asset_job("hackernews_job", selection=AssetSelection.all())
# Schedule the HN job to run every hour, using cron
hackernews_schedule = ScheduleDefinition(
job=hackernews_job,
cron_schedule="0 * * * *", # every hour
)
defs = Definitions(
assets=all_assets, jobs=[hackernews_job], resources={"llama": llama}, schedules=[hackernews_schedule]
)
And we’re done! Let’s run our pipeline and see the results.
In Dagit, go ahead and hit “Materialize all” assets.
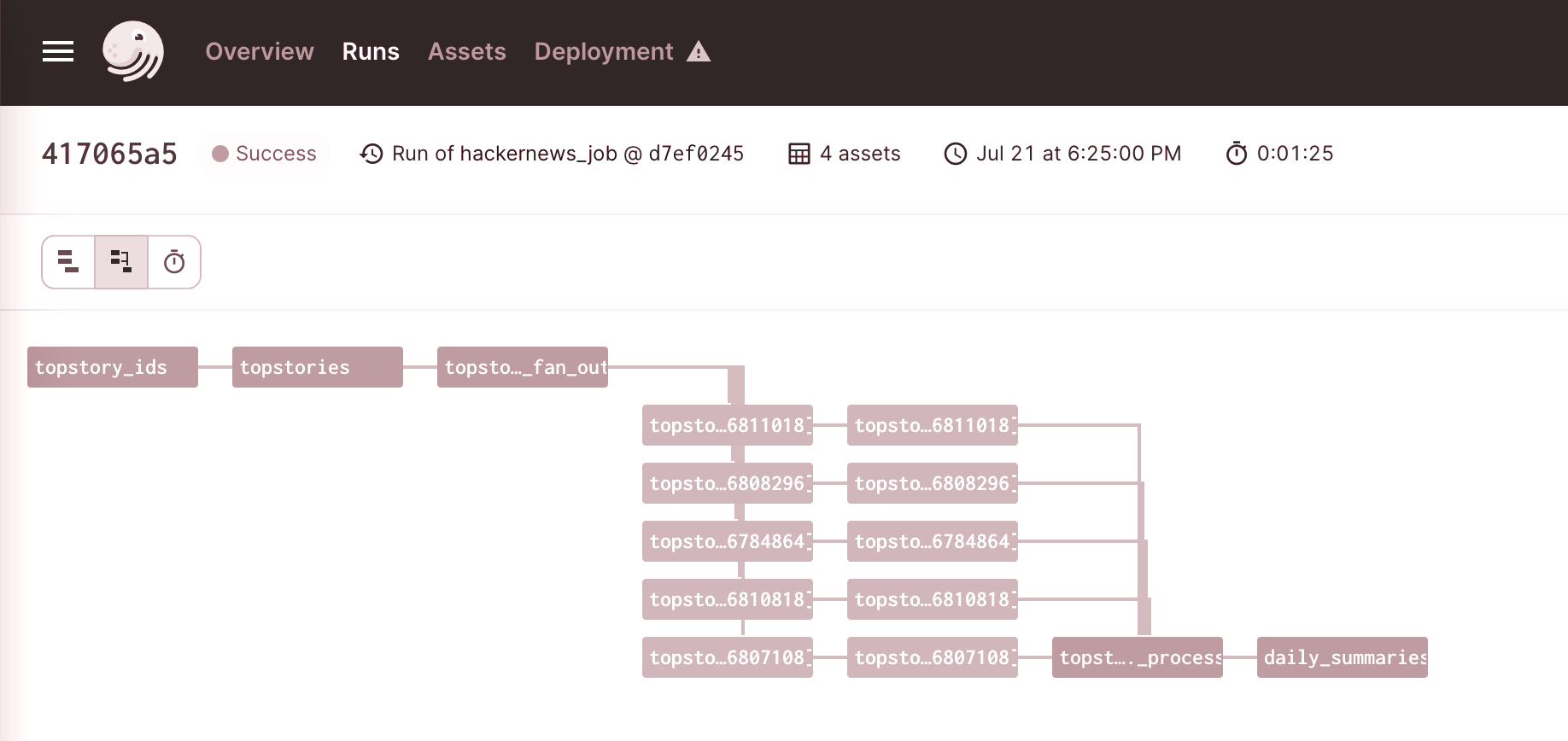
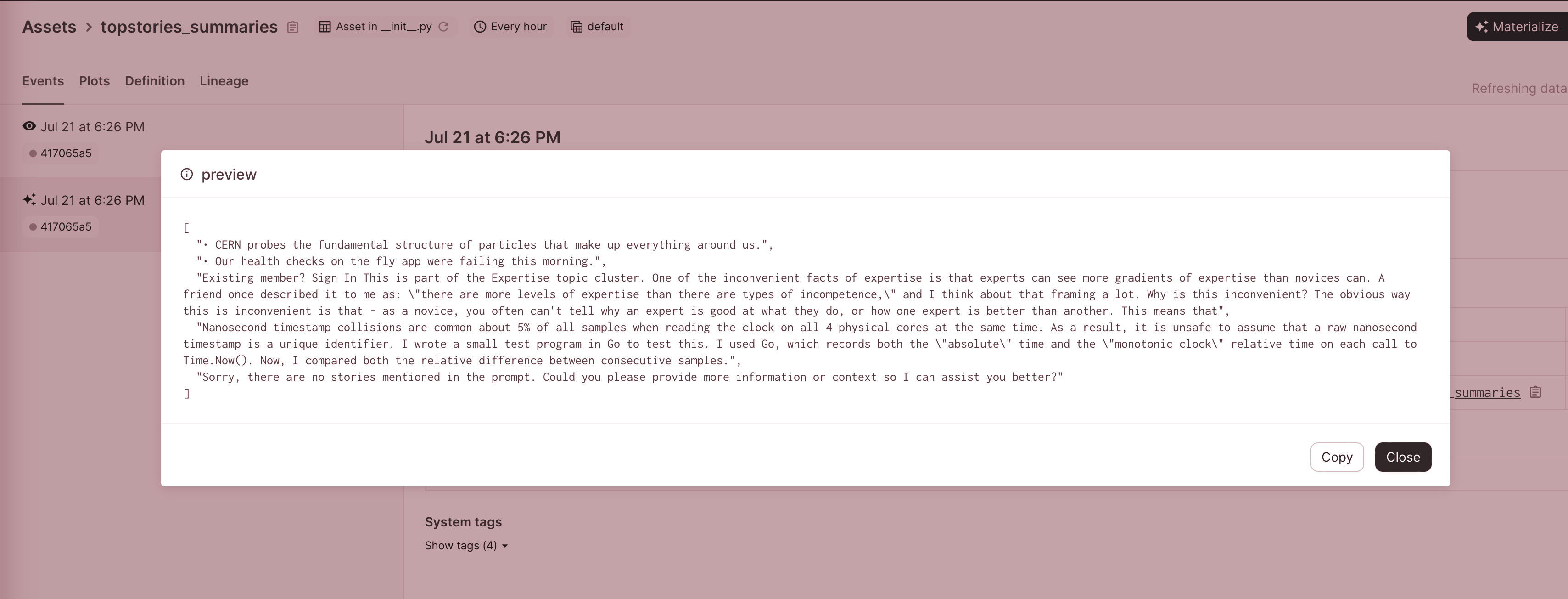
Now let’s check our materialisations:
Conclusion
While this is a very reductive way to look at the complex and powerful tool that Dagster is, I hope that I could pique your interest, or at least give you some sort of hope that data orchestration doesn’t have to suck, or be verbose to be useful.
If this was useful, or you would like more posts related to Dagster, please let me know by pinging me on socials @bruvduroiu@mastodon.social and @bruvduroiu on Twitter.
Also, all of the code is also available on GitHub - bruvduroiu/dagster-llama-pipeline
Cheers y’all!